לפני חצי שנה קיבלתי בשורה משמחת: המנהל שלי בחברת אוטודסק החליט לשלוח אותי לאירוע TECHX העולמי השנתי של החברה. מדובר באירוע שמיועד לכל אנשי התוכנה, חוויית המשתמש וה-IT של אוטודסק מכל רחבי העולם. מכיוון שאירועי החברה הגדולים מתקיימים כולם בארה”ב והסניף שאני עובד בו נמצא במלבורן, אוסטרליה, כמובן שאין תקציב לשלוח את כולם ולכן הרגשתי בר-מזל על ההזדמנות הנדירה.
לשמחה הוסיפה העובדה שהאירוע התקיים בניו-אורלינס, לואיזיאנה, שזו עיר שתמיד רציתי לבקר בה. מי לא ירצה בעצם? מדובר במולדת הבלוז והג’אז, עיר עם מורשת ספרדית, צרפתית, אפרו-אמריקאית, ילידית-אמריקאית ומה לא? אוכל עשיר, אדריכלות ייחודית, וכמובן עיר שבמרכזה זורם לו נהר המיסיסיפי רחב הידיים במלוא הדרו.

אז קפצתי על מטוס (או שניים) והגעתי לניו-אורלינס. העיר עצמה, על שלל מועדוני הג’אז שבה, המסעדות והמוזיאונים, לא אכזבה. גם הכנס המקצועי אורגן לעילא ולעילא: בין מגוון ההרצאות והסדנאות הרגילים, דאגו לסדר לנו גם אולם הפעלות ענק: קצת כמו לונה-פארק או אירוע יום הולדת אבל לגיקים מקצועיים. ועל אחד הדוכנים באולם הזה אני מעוניין להרחיב: אליפות ה-DEEPRACER של אמאזון.
התחרות
עוד לפני שבכלל עליתי על מטוס, כשעוד הייתי עסוק בלהזמין מקום בבית המלון, נרשמתי לתחרות המדוברת. לא ממש ידעתי על מה מדובר אבל השילוב בין תכנות, למידת מכונה, אמאזון ומכוניות מירוץ נשמע קורץ במיוחד. עודדו אותנו לקרוא את המבוא ולתרגל את ה-TUTORIAL כדי שכשנגיע נוכל מיד להשתלב בתחרות. לפרטים: https://aws.amazon.com/deepracer/
כשהגעתי למלון, כבר ידעתי פחות או יותר במה מדובר. כבר נרשמתי כמתחרה וכל שנותר לי הוא להיכנס לחשבון שפתחו עבורי ב-AWS ולכתוב קוד קצר.
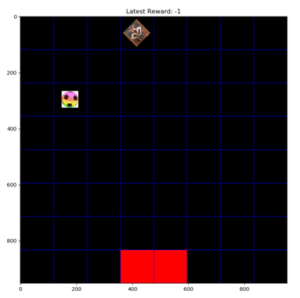
בגדול, מדובר על מכונית מירוץ בגודל בינוני, שבתוכה מחשב קטן (את מי שמעניין המפרט הטכני, הוא מופיע פה). כמו כל מירוץ, המטרה היא לעבור מסלול שלם בזמן הקצר ביותר האפשרי. אבל כאן מגיע גם ה”טוויסט”: למכונית אין ממש שלט סטנדרטי שמאפשר להזיז אותה ימינה ושמאלה, להאץ או להאט. כל מה שיש זה ממשק WEB שמאפשר למשתמש ללמד את המכונית כיצד להתנהג על גבי המסלול. איך “מלמדים” מכונית משהו?
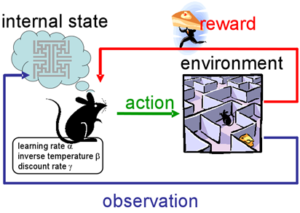
כאן בדיוק אנחנו אמורים לצלול עמוק למושג שצובר תאוצה בשנים האחרונות: למידה מתגמלת (או חיזוקית) :REINFORCEMENT LEARNING את מי שזה מעניין, הנה עמוד שמסביר בצורה לא רעה במה מדובר ולמעשה בבלוג הזה נכתבו כבר כמה כתבות בתחום (ביחרו מעלה את התגית Reinforcement Learning) ותראו את כולן.

קוד בקרה ולא קוד שליטה
משתמש הקצה כותב SNIPPET קצר של קוד (בשלל שפות אפשריות, זה לא ממש משנה איזו). קטע הקוד אמור “לתגמל” את המכונית בנקודות בכל פעם שהיא מתקדמת בתוך מה שהסנסורים שלה מזהים כחלק מהמסלול.
קיימות כ-30 פונקציות ספרייה שהמערכת מספקת שמכילות מידע לגבי מה שהסנסורים קולטים ומאפשרות לשלוט על המכונית ברמה בסיסית אך מספקת: סיבוב הגלגלים בזווית של עד 30 מעלות, התקדמות במהירות מסויימת או עצירה מוחלטת.
איך מתגמלים? בערך כמו שמאלפים כלב: נותנים למכונית פקודה (סעי קדימה) ונותנים ניקוד לפי המצב שלה בכל פעם שמקבלים “אירוע” מהסנסורים. המכונית יצאה מהמסלול ולא נרשמה התקדמות משמעותית? מורידים נקודה. המכונית התקדמה אך שני גלגלים יצאו החוצה? מעניקים שתי נקודות. המכונית התקדמה משמעותית וכולה נמצאת בתוך המסלול? חמש נקודות!
לכל אחד ואחת יכולה להיות “טקטיקת אילוף” משלהם אך הרעיון הכללי תמיד נשמר: לעודד את המערכת לצבור כמה שיותר נקודות.

האימון
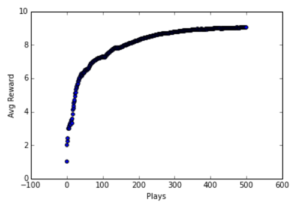
השלב הבא הוא “לאמן” את המכונית: מעלים את קטע הקוד לענן של אמאזון ונותנים למערכת להתאמן על גבי מסלול שדומה עד כמה שאפשר למסלול שעליו תתקיים התחרות. בשלב זה עוד לא צריך את המכונית עצמה. כל מה שהמערכת צריכה זה את קטע הקוד הקצר שכתבתם. היא כבר תדאג לבד להריץ סימולציות שונות, על פי פרמטרים שונים שתזינו לה: כמה סימולציות להריץ, מה תהיה המהירות ההתחלתית של המכונית? מה המהירות המקסימלית, אילו הגבלות נוספות להטיל על המערכת וכו’.
השלב הבא הוא לתת למערכת לעבוד, לרדת לבר לשתות משהו ולהכיר קולגות מרחבי העולם או לקפוץ לטיול קצר לאורך המיסיסיפי. אחרי כשעה המערכת כבר למדה מספיק מהי הדרך הטובה ביותר לנהוג את המכונית על גבי המסלול על פי ההתנהגות שקבעתם לה.
כל מה שנשאר בשלב זה היה לדבר עם קולגות שהתלהבו גם הם מהדוכן של אמאזון והתנסו במירוץ אמיתי עם מכונית DEEPRACER אמיתית, לקבל קצת טיפים (סע לאט! אל תעודד נהיגה מהירה מדי, הסנסורים לא מספיק רגישים כדי לקלוט המון מידע במהירות גבוהה) ולצפות במתמודדים שונים מנסים את מזלם, לפני שאני מביא את ה-USB DRIVE שלי כדי לעלות על המסלול.
למעשה ה-“קופסה השחורה” של המודל נוירונים מתאמן באופן וירטואלי על בסיס משטר הניקוד שתיכנתנו אותו ולבסוף הוא מוכן לנהג את המכונית במירוץ האמיתי (בעולם הפיסי).

לסיכום
התחרות עצמה בין באי הכנס היתה מוצלחת. כמאה משתתפים ניסו את מזלם בתחרות שנמשכה יומיים. הזוכה במקום הראשון עם התוצאה המרשימה של קצת מעל 6 שניות זכה במכונית DEEPRACER. יתר המשתתפים (ואני ביניהם) הסתפקו בחולצות, כובעים וקפוצ’ונים מעוטרים בלוגו המפורסם של AWS.
בסך הכל היה מדובר בחוויה מעשירה ומלמדת שבהחלט הצליחה לגרות את הסקרנות שלי לגבי תחום למידת מכונה ועל הדרך להכיר לא מעט אנשים.