
אחת מנגזרות מהפכת הלמידה העמוקה היותר מעניינות התרחשה (ועדיין מתרחשת) בתחום הReinforcement Learning. הניצחון של אלגוריתם של DeepMind על אלוף העולם הסיני ב GO ב 2016, והאלגוריתמים שלהם שלומדים לשחק משחקי אטארי ישנים מתוך התמונה שרואים על המסך (ללא הכנסת מודל כלשהוא אלא רק ע”י ניסוי וטעייה במשחק).
בעולם ה Reinforcement Learning (למידה חיזוקית) ישנו סוכן Agent שחי בסביבה כלשהיא Environment ויש לו אוסף כלשהוא של פעולות Actions שיכול לעשות בסביבה. הסוכן מקבל תגמול Reward מהסביבה בהתאם לפעולותיו ובכל רגע נתון הסוכן נמצא במצב State כלשהוא. מצב (state) הינו כל האינפורמציה הידועה לסוכן (זה שמקבל את ההחלטות בכל רגע).
סצנריו זה מתאים לתוכנה שמחשקת משחקי מחשב, או לרובוט שיש לו משימה כלשהיא בעולם הפיסי, או לרכב אוטונומי ועוד…
בכתבה זו אסקור בעיה בסיסית ופשוטה Multi-Armed bandit (אם טעיתי בתרגום בכותרת אנא תקנו אותי…) עם מצב state בודד ומספר קטן של אפשרויות פעולה action בכל תור (כמספר הידיות).
איך להרוויח הכי מהר שאפשר בקזינו ?
תארו לעצמכם קזינו בו מכונות המזל עקביות בהתנהגותם הסטטיסטית אך אינן זהות זו לזו. במילים אחרות יש הרבה מכונות מזל (ידיות) שלכל אחת יש את המזל\נאחס הקבוע שלה. ז”א יש אחת שבממוצע תוציא לך 10$ ויש כאלו שיוציאו בממוצע 1$. (כשאומרים בממוצע מתכוונים שהמכונה תוציא בכל פעם סכום אחר, אך לאחר הרבה משחקים תשאף לערך ממוצע אחד). כמובן שלכל משחק גם יש עלות, נניח 5$ כך שההשקעה תחזור (אם בכלל) רק אחרי הרבה משחקים, וכדי לבחור באילו מכונות לשחק ובאילו לא.

אז אם אתה כבר יודע מהן המכונות שמוציאות בממוצע הרבה תוכל לשחק רק בהן, אבל בהתחלה אינך יודע כלום, מה גם שאפילו ומצאת מכונה כזו טובה, תמיד יחלפו במוחך המחשבות שיש אפשרות שיש מכונות אפילו יותר מוצלחות איתן תוכל להרוויח יותר כסף ויותר מהר.
בבעיית הידיות (הקזינו) יש מצב state יחיד כי בכל רגע נתון הסוכן יודע שיש את אותם האפשרויות לפעול ואין לו מידע חדש מהסביבה (לא כולל מידע שהוא צבר מניסיונותיו). בעיות עם ריבוי מצבים הינן למשל לשחק ב GO או רובוט שלומד לפתוח דלת על בסיס מה שרואה (ז”א מה שמתקבל ממצלמה שמותקנת עליו). באלו יש המון מצבים states כי האינפורמציה מהסביבה כל רגע\תור משתנית.
בעיית הפשרה בין מחקר ופיתוח
אז במה להשקיע את הניסיונות משחק שלך (שעולות לך 5$ לכל ניסיון) ?
בלשחק במכונה מוכרת או בלחקור ולהכיר עוד מכונות ? (נקראת דילמת ה – exploration\exploitation)
או אפילו בלהכיר יותר טוב מכונה שכבר קצת הכרנו, כי למשל אם שיחקנו במכונה ועד עתה אלו היו הזכיות שלנו:
2,5,3 אז הממוצע בינתיים הינו 3.333, ואם נשחק במכונה זו עוד הממוצע כנראה ישתנה, וככל שנשחק במכונה יותר כך “נאמין” לממוצע שיוצא לנו יותר (כי הרי אמרנו שהמכונות מכווננות על ממוצע מסוים)
הפתרון
אחד הפתרונות לבעיה זו נקרא ε-greedy (אפסילון התאב בצע J) שזה אומר, קבע ערך כלשהוא בין 0 ל 1 (אפסילון) ואז בכל פעם הגרל ערך אקראי בין אפס לאחד. אם גדול מאותו קבוע אפסילון אז שחק במכונה אקראית כלשהיא, אחרת שחק במכונה שעד עכשיו הממוצע שלה הכי טוב. בדרך זו מצד אחד תרוויח (כי לעיתים תשחק במכונה הכי רווחית למיטב ידיעותיך באותו הרגע) מצד שני תרחיב את הידע שלך (כי לעיתים תנסה מכונות אחרות).
בשיטה זו הרווחים יגדלו כי ההכרות שלך עם הקזינו תגבר ותדע איפה יותר כדאי לשחק, אך בשלב מסויים הרווחים יגדלו פחות ואף יישארו קבועים כיוון שמיצית את ההכרות עם הקזינו, ז”א מצאת את המכונה הכי ריווחית ולכן המחקר שלך כבר לא מניב הגדלת רווחים יותר. ראה גרף רווחים כתלות בכמות משחקים:
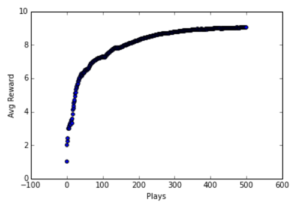
גם אם במשחקים הראשונים חשבנו שמכונה מסוימת היא הכי ריווחית והיא לא (כי כאמור הממוצע האמיתי מתגלה לאחר הרבה משחקים, וכל משחק בודד יכול להניב רווח כלשהוא שרחוק מהממוצע) אז זה די מהר יתוקן. כי לאחר עוד כמה משחקים במכונה שנראית הכי ריווחת נגלה שהיא לא כזו רווחית כפי שחשבנו בהתחלה ומכונה אחרת תוכתר להיות הכי ריווחית.
פתרון כללי יותר לבעיה נקרא Softmax Action Selection אשר לפיו בחירת הפעולה בכל רגע גם תוגרל אך לא רק בין שתי אפשרויות כמקודם (בין המכונה הכי ריווחית עד כה או מכונה כלשהיא אקראית). אלא תוגרל מבין כל האפשרויות (כל המכונות) אך לפי התפלגות שנלמדה עד עתה. ז”א נגריל מכונה לפי מידת הידע שלנו על הריווחיות שלה. ככה עדיין המכונה הכי טובה (לפי הידע של אותו הרגע) תיבחר הכי הרבה, אך גם המכונה השניה הכי טובה (לפי הידע של אותו הרגע) תיבחר השניה הכי הרבה. מכונות שאין לנו עליהן מידע כלל ייבחרו הכי פחות. בשיטה זו פחות נפסיד בהתחלה ויותר נמצה את הידע שלנו בסוף.
