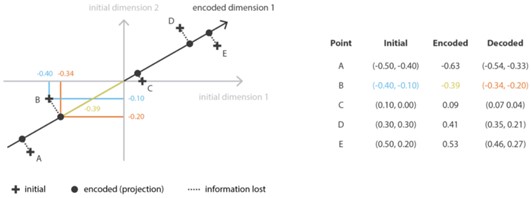
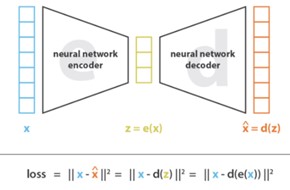
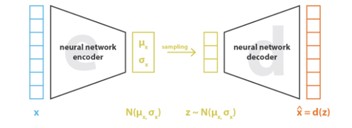
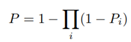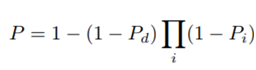בכתבה זו, נצלול אל בעיית זיהוי הדובר שנעשית פופולרית יותר ויותר בשנים האחרונות. נבין את המוטיבציה להתמודדות עם הבעיה, נגדיר את הבעיה היטב, ונסקור את הכלים השונים, האלגוריתמים והמרכיבים במערכת זיהוי דובר קצה אל קצה מבוססת למידת עמוקה.
מוטיבציה
ביומטריה קולית היא טכנולוגיה שמתבססת על זיהוי דפוסי קול כדיי לאמת זהות של אנשים. הדבר אפשרי, מכיוון שכל ייצור חי, שונה פיזיולוגית מרעהו וכך גם בית הקול וחלל הפה , שהם בעצם “מחוללי” אותות הדיבור שלנו. לכל בן אדם, קיימים מאפייני דיבור אקוסטיים ופונטים שייחודיים רק לו. כמו שלא קיימים 2 אנשים עם אותה טביעת אצבע, כך גם לא קיימים 2 אנשים עם אותה חתימה קולית.
בשנים האחרונות, השימוש במערכות בעלות ממשק משתמש קולי נעשה חלק שגרתי בחיינו– אנחנו מתקשרים בעזרת פקודות קוליות עם מערכות הרכב, נותנים פקודות קוליות לעוזרים “ווירטואלים” (סירי, אלכסה) אשר מבצעים פעולות בסמארטפונים ובמכשירי הבית ואפילו נעשה שימוש בקול שלנו עבור אפליקציות פיננסיות ובנקים על מנת להזדהות ולבצע פעולות רגישות.
ככל שמבינים כמה מידע ופעולות רגישות המכשירים האישיים שלנו יכולים להכיל ולבצע, ככה זה ברור שאימות ביומטריה קולית חייב להיות מרכיב בלתי נפרד באפליקציות אלה ובחיינו.
הגדרת הבעיה
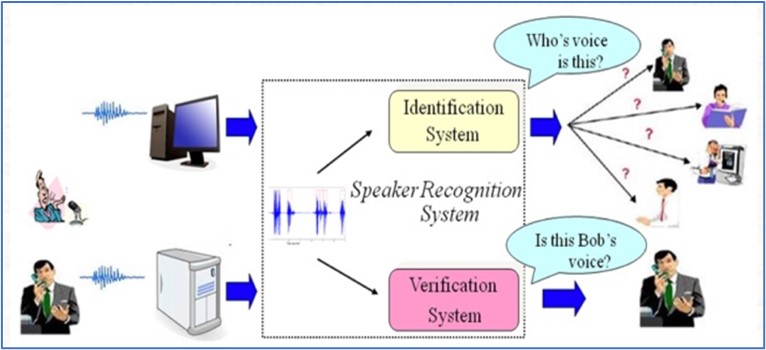
זיהוי דובר, זה תהליך שבו בהינתן קטע דיבור, יש להחליט באופן אוטומטי מי הדובר בקטע על סמך המידע הכלול באות הדיבור. להבדיל ממשימת זיהוי הדיבור בה נשאלת השאלה “מה נאמר?” כאן נשאלת השאלה “מי אמר?”
את בעיית זיהוי הדובר מקובל לחלק ל2 תתי בעיות:
* סיווג דובר מתוך מאגר סגור של דוברים – בהינתן X דוברים ידועים למערכת, ובהינתן קטע דיבור חדש y, על המערכת לזהות למי מבין X הדוברים המוכרים קטע y שייך. או במילים אחרות, המטרה היא למצוא מי מהדוברים הידועים נשמע הכי קרוב לקטע הדיבור החדש שהתקבל במערכת.
* אימות דובר –בהינתן קטע דיבור של דובר לא ידוע וטענה לזהות הדובר בקטע עבור דובר מוכר למערכת, יש להחליט האם הטענה נכונה או שלא. במילים אחרות, בהינתן 2 קטעי דיבור (של דובר לא ידוע ושלא דובר מוכר) על המערכת להחליט האם 2 הקטעים שייכים לאותו דובר.
בכתבה, נתייחס לבעיית זיהוי הדובר כאל בעיית אימות דובר.
דרך נוספת להסתכלות על הבעיה היא הקבלה של המערכת לזיהוי דובר למערכת גישה שיש לה מידע על אנשים “רשומים” (מאופשרי גישה), ובהינתן קטע דיבור של דובר מועמד שטוען שהוא “משה” (משה מאופשר גישה), המערכת צריכה להחליט האם זה אכן משה ולאפשר גישה או לחלופין לקבוע שהדובר המועמד הוא מתחזה ולחסום גישה.
מאפיין נוסף שמתווסף לבעיית זיהוי הדובר הוא האם הבעיה “תלוית טקסט” או “לא תלוית טקסט”. כאשר הבעיה תלוית טקסט, כל קטעי הדיבור הנקלטים במערכת מוגבלים לטקסט ספציפי וכאשר הבעיה לא תלויה, המערכת צריכה לזהות את הדובר ללא תלות בתוכן ואורך האימרה. כאמור, ההבדל היישומי בין הגישות, הוא שעבור הראשונה, המערכת תנתח בעיקר את מאפייני הדיבור הפונטים של הדובר בעוד בגישה השנייה, המערכת תתמקד בתכונות האקוסטיות הייחודיות לכל דובר. הבעיה הלא תלוית טקסט שדורשת התמודדות עם קטעי דיבור באורכים שונים, נחשבת למורכבת יותר מכיוון שהשונות בין קטעים השייכים לאותו דובר תהיה גדולה יותר משמעותית, אך מצד שני פתרון שלה יהיה הרבה יותר אפליקטיבי לחיי היומיום.
בכתבה זאת, אנו מתייחסים לבעיית זיהוי דובר לא תלוית טקסט.
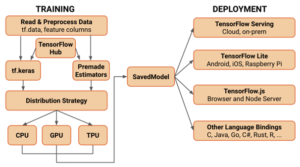
מערכת לזיהוי דובר מבוססת למידה עמוקה
מערכת לזיהוי דובר מבוססת למידה עמוקהממומשת על ידי חיבור של חמשת השלבים הבאים:
1. הוצאת פיצ’רים לדאטה הגולמי.
2. אימון מודל רשת נוירונים לסיווג דוברים מקבוצה סגורה.
3. הוצאת ווקטור זהות לכל דובר “נרשם למערכת” או “מועמד” על ידי למידת מעבר מהמודל שאימנו בשלב הקודם.
4. הוצאת תוצאת תאימות עבור 2 קטעי דיבור.
5. קבלת החלטה.
ניתן לראות את סכימת המערכת הבסיסית באיור הבא:
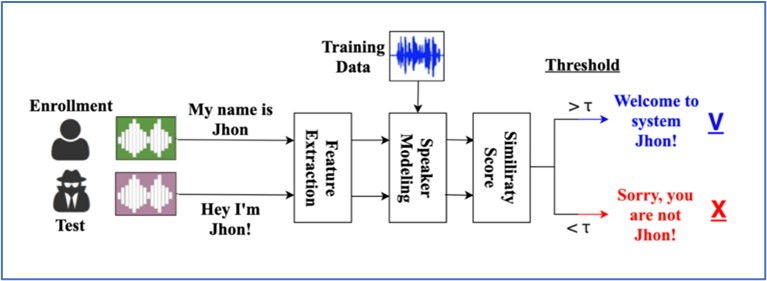
כעת, נעבור לחלק המעניין בו נסביר על כל שלב במערכת, ולאחריו תדעו איך ניתן לזהות דובר בעזרת למידה עמוקה 🙂
1. הוצאת פיצ’רים
בשלב הראשון, יש לבצע ווקטוריזציה וניקוי לדאטה הגולמי (קטעי אודיו).
ווקטוריזציה היא הוצאת פיצ’רים בדידים מקטעי הקול ע”י דגימה של האות וביצוע מניפולציות מתמטיות מתחום עיבוד האותות. כאמור, אנו מתמקדים בבעיה לא תלוית טקסט לכן נרצה שהפיצ’רים שלנו יכילו מידע אקוסטי על קטעי הקול,קרי מידע תדרי.
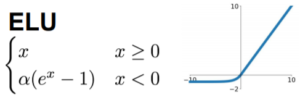
להוצאת הפיצ’רים נשתמש באלגוריתם ה(MFCC(Mel Frequency Cepstrum Coefficient אשר נפוץ מאוד גם בעולם זיהוי הדיבור. הייחודיות באלגוריתם זה היא העבודה במרחב התדר של האות וההתחקות אחר הדרך הפיזיולוגית בה האוזן האנושית מדגישה את מנעד התדרים ע”י שימוש בסולם MEL (מתייחס לתדר או גובה הצליל הנשמעים על ידי האוזן האנושית ביחס לערכים הנמדדים בפועל. לבני האדם הרבה יותר קל להבחין בשינויים קטנים בגובה הצליל בתדרים נמוכים)
לאלגוריתם הMFCC מספר שלבים:
1. אות הדיבור הרציף נדגם ונחתך לפריימים נחפפים בעלי גודל זהה.
2. על כל פריים, מופעלת התמרת פורייה דיסקרטית (Discrete Fourrier Transform) ומחושבת האנרגיה בספקטרום התדרי לקבלת ייצוג האות בתחום התדר.
3. הייצוג התדרי של הפריימים עובר דרך פילטר חלונות ((hamming אשר מכווצים ומורחבים לפי סולם MEL. מספר החלונות שנבחר, יהיה מספר הפיצ’רים שנקבל עבור כל פריים.
4. קבלת פיצ’רי הMFCC תהיה על ידי הפעלת התמרת קוסינוס בדידה (Discrete Cosine Transform) על ווקטורי הפיצ’רים, שנועדה לייצר דה-קורלציה בין הפיצ’רים בווקטור.
לאחר הוצאת הפיצ’רים עבור כל פריים, מתבצע סינון פריימים שבהם אין דיבור (Voice Activity Detection).
בצורתו הבסיסית ביותר, סינון המקטעים השקטים מתבסס על חישוב אנרגיית הפריימים, והשלכת הפריימים השקטים בעזרת אחוז סף שנקבע מראש. קיימים גם אלגוריתמים מתקדמים יותר לסינון רעשים בעזרת רשתות נוירונים אשר לומדים לזהות קטעי דיבור מתוך סדרת ווקטורי פיצ’רים.
2. אימון מודל לסיווג דוברים מקבוצה סגורה
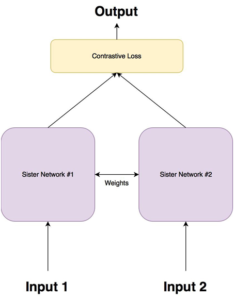
בשלב השני, נרצה לייצר מודל מאומן אשר יקבל אליו בכניסה סדרת פריימים המרכיבים קטע דיבור יחיד, והמוצא יהיה ווקטור זהות לדובר הרלוונטי אשר יכיל את המאפיינים בעלי תכונות האפלייה החזקות ביותר שבעזרתם ניתן לאמת דוברים. כלומר, עבור אוסף ווקטורים המייצג קטעי דיבור שונים שייכים לאותו דובר, נרצה שהשונות תהיה מינימאלית, ואילו עבור אוסף ווקטורים השייכים לקטעים של דוברים שונים השונות תהיה מקסימלית.
תכונה קריטית שצריכה להיות לווקטורי הזהות, היא שהם צריכים להיות בעלי גודל זהה ללא תלות באורך קטע הדיבור שעל בסיסו הם חולצו, על מנת שבהמשך נוכל “להשוות ביניהם”. בהמשך נראה כיצד הגבלה זאת משפיעה על ארכיטקטורת המודל שלנו.
אחד האתגרים הגדולים ביותר עבור משימת אימות הדובר, הוא המחסור בדאטה עבור דוברים הרשומים במערכת. בדרך כלל יהיו לנו קטעים בודדים עבור כל דובר, ואי אפשר רק על סמך קטעים אלה לבנות מודל סטטיסטי לדובר הרלוונטי, שבהמשך נוכל להשוות אל מול קטע הדיבור החדש והלא מוכר שנכנס למערכת וטוען לזהות.
לכן, נשתמש בשיטת למידת מעבר בה ניקח קבוצה סגורה של קטעי דיבור מתוייגים לפי דוברים, ונאמן מודל של רשת נוירונים, שתפקידו יהיה לבצע סיווג דובר מתוך הקבוצה הנתונה(כמו שהסברנו בתחילת הכתבה).
לאחר שהמודל יהיה מאומן ויסווג את הדוברים מהקבוצה הסגורה בצורה טובה, נצא מנקודת הנחה, שנלמדה הטרנספורמציה המיטבית שמופעלת על סדרת פריימים המרכיבים קטע דיבור וממירה אותם לווקטור הזהות של הדובר בקטע, בעל תכונות האפלייה כנדרש.
את ווקטור הזהות המייצג כל דובר על סמך קטע הדיבור שנכנס למערכת, נוציא מאחת השכבות האחרונות של מודל זה.
המודל המסווג בנוי מ3 חלקים:
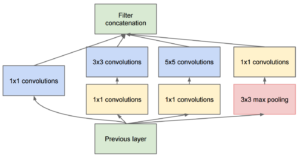
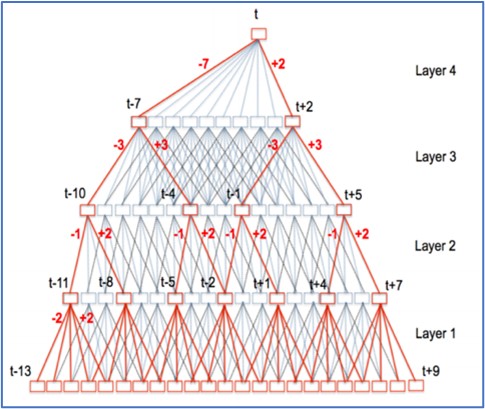
1. שכבות ייצוג פריים (frame-level)– לחלק הזה ייכנסו סדרות של פיצ’רים המייצגים את הפריימים שמרכיבים את קטע הדיבור. במאמר https://www.danielpovey.com/files/2018_icassp_xvectors.pdf שהציג לראשונה את שיטת ה x-vector שהפכה לSOTA בתחום, נעשה שימוש בארכיטקטורת Time Delay Neural Network (מופיעה באיור) שהיא אימפלמנטציה של רשת קונבולוציה חד מימדית, כאשר הקלט לרשת הוא שרשור של פריים במקום ה-t, יחד עם מספר קבוע של פריימים עוקבים ואוחרים לו. בכל שכבה יש קונטקסט קבוע בין הייצוגים של הפריימים (ניתן להתייחס אל זה כאל פילטר בגודל ספציפי) וככל שמעמיקים ברשת ככה הקונטקסט גדל (ניתן לראות בתמונה את הקווים האדומים שמסמנים את הקונטקסט בכל שכבה). בצורה הזאת, אנחנו גם מרוויחים ניצול מיטבי של המידע עבור כל פריים וגם מתאפשר חישוב בצורה יעילה (מבלי לחשב קשרים בין פריימים רחוקים ללא קורלציה).
אפשרות נוספת למימוש שלב הפריים הוא בעזרת ארכיטקטורת RESNET, כאשר הקלט הוא מטריצה שמייצגת קטע דיבור ככה שכל שורה היא ווקטור פיצ’רים של פריים (פריימים עוקבים מיוצגים ע”י שורות סמוכות במטריצה).
2. שכבה חשובה מאוד במודל המסווג שלנו היא שכבת ה”איגום” (pooling layer). מכיוון שהמערכת צריכה לעבוד עם קטעי דיבור באורכים שונים, יש צורך בשכבת מעבר משלב ייצוג הפריים לשלב ייצוג ה”קטע” (segment-level).
שכבת האיגום , אוגרת את כל הייצוגים של הפריימים לאחר מעברם בשכבות הרשת הראשונות ומבצעת עליהם מניפולציה סטטיסטית על מנת להוציא ווקטור יחיד בגודל קבוע ללא תלות בכמות פריימים שאגרה.
דוגמא פשוטה לשכבה כזאת היא שכבת איגום סטטיסטית שמחשבת פרמטרים סטטיסטים (תוחלת וסטיית תקן) עבור כל הפריימים השייכים לקטע ולכן המוצא שלה יהיה תלוי במימד השכבה שבקצה הרשת ולא בכמות הפריימים. שכבות איגום חכמות יותר יכולות לשלב attention על מנת לחשב ממוצע משוקלל חכם בין כל הפריימים או שכבת Learnable Dictionary Encoding שלומדת פרמטרי קידוד יחד עם מילון מובנה עבור כל פריים על מנת להוציא את הייצוג המיטבי לקטע.
3. השכבה האחרונה במודל המסווג, היא שכבת הסיווג, שנעשה בה שימוש רק במהלך אימון המודל (ולא בשלב למידת המעבר). דוגמא פשוטה לשכבה כזאת היא softmax עם cross entropy loss סטנדרטי כאשר כמות המוצאים זהה לכמות הדוברים במאגר האימון הסגור.
3. חילוץ ווקטור זהות דובר מהמודל המסווג
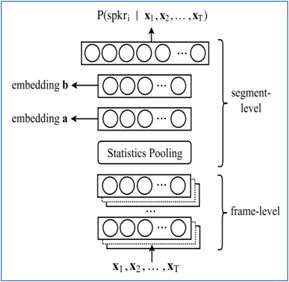
לאחר שהמודל המסווג אומן היטב, בהינתן קטע דיבור חדש, נשתמש בלמידת מעבר ונבצע feed-forward לווקטורי הפריימים המרכיבים אותו. חילוץ וקטור זהות הדובר יתבצע מאחת השכבות הממוקמת לאחר שכבת ה”איגום” ולפניי שכבת הסיווג (מוצא) של המודל.
בתמונה, ניתן לראות מודל מחלץ שמאומן ע”י דאטה סגור של T דוברים. ווקטור הזהות מחולץ מאחת משכבות הembedding.
4. תוצאת תאימות עבור 2 קטעי דיבור
השלב הרביעי בתהליך מתחיל לאחר שכבר חילצנו ווקטורי זהות דובר עבור 2 קטעי דיבור, וכעת יש להשוות ביניהם, או במילים אחרות להוציא להם תוצאת תאימות (similarity score).
תוצאת התאימות המתאימה ביותר למקרה שלנו היא יחס הlikelihood בין 2 היפותזות:
* 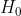 – 2 קטעי הדיבור שייכים לאותו הדובר
– 2 קטעי הדיבור שייכים לאותו הדובר
* 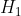 – 2 קטעי הדיבור שייכים לדוברים שונים
– 2 קטעי הדיבור שייכים לדוברים שונים
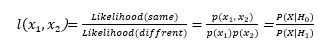
כאשר  מסמלים את ווקטורי הזהות שחולצו ל 2 קטעי הדיבור. ניתן לראות שהתוצאה נעה בין 1 (קטעים זהים) ל 0.
מסמלים את ווקטורי הזהות שחולצו ל 2 קטעי הדיבור. ניתן לראות שהתוצאה נעה בין 1 (קטעים זהים) ל 0.
במצב אידאלי, בו יש ברשותנו מספיק דאטה עבור כל דובר רשום במערכת, ניתן לבנות מודל סטטיסטי עבור כל קלאס (דובר) ובעזרת GMM לדוגמא, לחשב את תוצאת התאימות בין קטע דיבור של דובר לא ידוע לדובר הקיים במערכת שלזהות שלו הוא טוען.
אבל במצב הריאלי, כאשר אין מספיק דאטה ברשותנו, נרצה להשתמש במודל סטטיסטי חכם אשר מאומן ע”י צמדים של קטעי דיבור בעלי תיוג של שייכות לאותו דובר. מודל הPLDA(Probability Linear Discriminant Analysis) עושה שימוש במטריצות הפיזור של בתוך הקלאס ומחוץ לקלאס
(between-class and within-class scatter matrix), אשר מחושבות ע”י צמדי קטעי האימונים, ומגדיר משתנה חבוי שהוא משתנה הקלאס שיוגדר להיות משתנה אקראי גאוסי (רציף לעומת הבדיד במודל הGMM). בעזרת משתנים אלו, מודל הPLDA ממדל את ההסתברות לדובר כלשהו וגם את ההסתברות המותנת של קטע דיבור בהנתן דובר כלשהו. בעזרת התפלגויות אלה, ונוסחאת ההסברות השלמה, ניתן עבור 2 קטעי דיבור, לחשב את תוצאת התאימות ביניהם.
בהסבר הקצרצר כאן חסכתי לכם את הפיתוחים המתמטיים של המודל, אבל מידע נוסף למתעניינים נמצא בקישור הבא: https://link.springer.com/content/pdf/10.1007/11744085_41.pdf
קבלת החלטה
השלב האחרון בתהליך זיהוי הדובר, הוא קבלת ההחלטה של המערכת, האם 2 הקטעים שייכים לאותו דובר או שלא. תוצאת התאימות היא רציפה ולכן ההחלטה מתקבלת ע”י קביעת סף מראש, שאם התוצאה עוברת אותו, ההחלטה היא חיובית ולהיפך. קביעת הסף תתבצע בדרך כלל בהתאם לאפליקציית המערכת ול”מחיר” השגיאה.
בעולם זיהוי הדובר קיימות 2 שגיאות:
* שגיאת קבלה (False Alarm)– כאשר 2 הקטעים שייכים לדוברים שונים אבל המערכת מחליטה שהם שייכים לאותו הדובר
* שגיאת דחייה (False reject)– כאשר 2 הקטעים שייכים לאותו דובר אבל המערכת מחליטה שהם שייכים לדוברים שונים
ככל שבאפליקציית זיהוי דובר, מחיר שגיאת הקבלה גבוה יותר (לדוגמא, מערכת הזדהות לביצוע פעולות בנקאיות), נקבע את סף ההחלטה להיות גבוה יותר. לעומת זאת, כאשר מחיר שגיאת הדחייה גבוה יותר (לדוגמא, מערכת נוחות לביצוע פעולות בבית חכם באמצעות פקודות קוליות) נוריד את סף ההחלטה.
הערכת ביצועי המערכת
חלק בלתי נפרד מכל תהליך של פתרון בעיה בעזרת מערכת כלשהי, הוא ניתוח ביצועי המערכת.
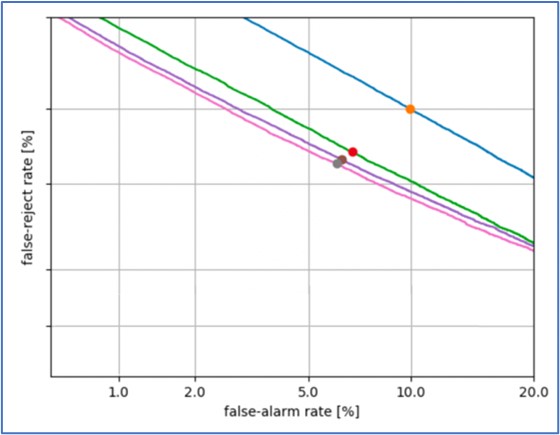
על מנת למדוד את ביצועי מערכת זיהוי הדובר, נשתמש בדאטה אבלואציה ובכלי גרפי שנקרא Detection Error Tradeoff Curve.
דאטה האבלואציה יורכב מצמדי “מבחן” של קטעי דיבור, ותיוג האם הם שייכים לאותו דובר או לא (target \ non-target). בגרף, הצירים מייצגים את יחסי שגיאות המערכת עבור סט אבלואציה של צמדי קטעי קול המתוייגיםכtarget או non-target.
נריץ את המערכת על טווח רחב של ספים, ועבור כל סף החלטה נמדוד את יחסי השגיאות. כלומר, עבור יחס שגיאת קבלה, נחשב את מספר השגיאות ביחס לכל הצמדים המתוייגים כ-non-target,ועבור יחס שגיאת דחייה נחשב את מספר השגיאות ביחס לכל הצמדים המתוייגים כ-target.
כל סף בו יחס השגיאות מחושב, הוא נקודה במערכת הצירים הקושרת בין 2 יחסי השגיאות. סוואפ על טווח רחב של ספים ייצור לנו עקומה שמתארת את ביצועי המערכת ביחס לשגיאות האפשריות.
ניתן לראות, שככל שהגרף קרוב יותר לראשית הצירים ככה ביצועי המערכת טובים יותר. נקודת עניין על הגרף היא נקודת הEqual Error Rate שמסמנת את ביצועי המערכת עבור נקודת עבודה בה יחסי השגיאות שווים.
בגרף הבא, ניתן לראות השוואה בין 4 מערכות שונות שנבדקו על אותו דאטה סט, הנקודות על הגרפים הן נקודות הEER:
לסיכום
תיארנו כאן את בעיית זיהוי הדובר לסוגיה והצגנו מערכת בסיסית מבוססת למידה עמוקה להתמודדות עם הבעיה. על מנת שהכתבה תתאים לקוראים מתעניינים מכל הרמות, השתדלתי לא להכנס לפיתוחים ואלגוריתמים מורכבים שבעזרתם ניתן להסביר לעומק חלק מהמודלים וכמו כן, לא הזכרתי תתי בעיות שמתלוות לבעיה הכללית כגון אי התאמת תחום דוברים, כיול של המערכות לנקודת עבודה או התמודדות עם דאטה מתחום לא ידוע מראש על מנת לפשט את הכתבה ככל האפשר.
אם לאחר קריאת הכתבה צצות לכם שאלות או שתרצו הרחבה נוספת בנושאים קשורים, מוזמנים לכתוב לי במייל ואשמח לנסות לעזור (-:
Barmadar13@gmail.com
linkedin.com/in/bar-madar-838b15160