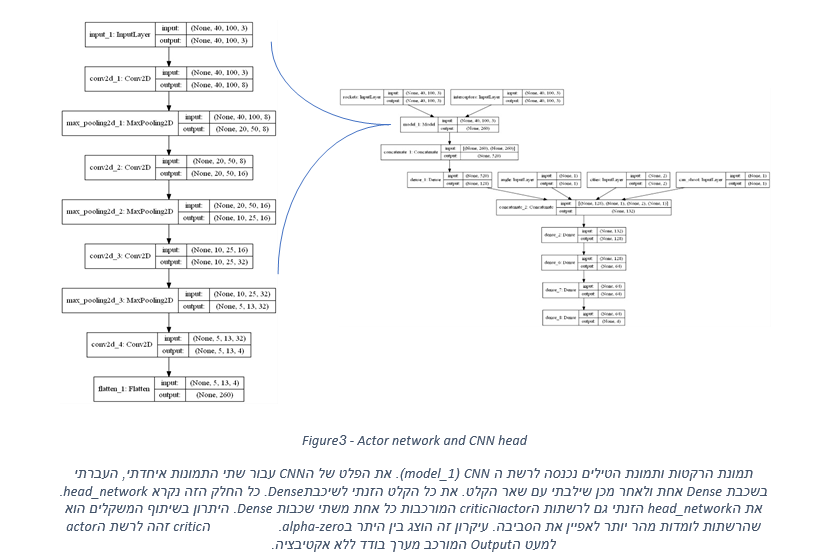
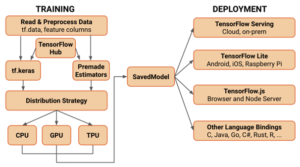
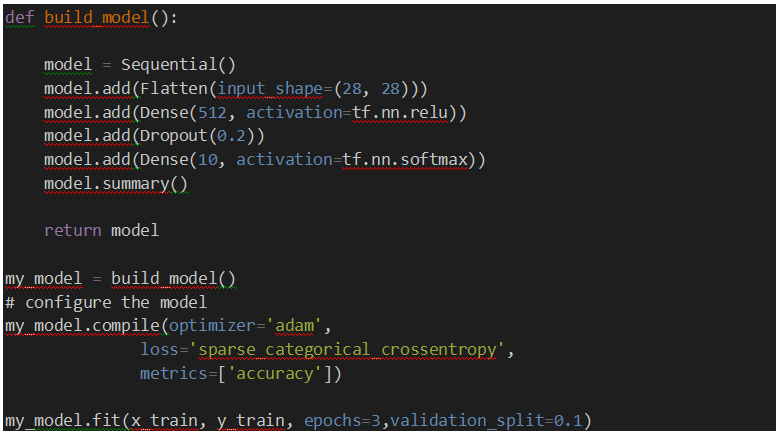
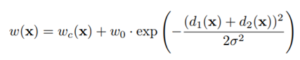איך מערכת המלצות עובדת ?
מערכת המלצות שואפת להכיר את הייחודיות של כל משתמש ע”י טעמו האישי והנושאים השונים אשר הוא מגלה בהם עניין, את איסוף הנתונים על המשתמש המערכת מאגדת עם נתוני משתמשים שדומים לו הנמצאים בתוך בסיס הנתונים וכך תציע פריטים שהמשתמש עשוי להתעניין.
מאיפה הנתונים על המשתמש מגיעים ?
- משוב מהמשתמש – לדוגמה דירוג ע”י 5 כוכבים או לייק, בצורה כזו המערכת מקבלת באופן מפורש אם המשתמש אוהב את המידע שבו הוא צופה, והמידע הזה עוזר למערכת לבנות פרופיל על נושאי ההתעניינות שלו. החיסרון שהמשתמש לא תמיד נוטה לבצע פעולה לדירוג ומידע כזה אל מול כמות משתמשים נוטה להיות דליל, מה שיכול להוביל שאיכות ההמלצות תהיה נמוכה. בסוג של המלצות דירוג לפי מספר כוכבים ישנה יותר מורכבות, כי יש אנשים שנוטים להיות ביקורתיים יותר או ביקורתיים פחות ולכן מה שאומר שדירוג שלושה כוכבים לאחד לא תהיינה בהכרח אותה משמעות לאחר.
- דרך נוספת לאיסוף מידע על המשתמש היא מהמשתמע מפעולותיו היזומות,
לדוגמה אם המשתמש לוחץ על קישור באתר אז המשתמע בפעולה שלו היא חיובית, כי ככל הנראה הוא מעוניין בסוג כזה של מידע, כתבה, סרטון, פרסומת או קנית מוצר כלשהו.
החיסרון הוא שישנם משתמשים הלוחצים על הקישור בטעות או באובייקט כמו תמונה המקושר לקישור ואין בהכרח מאחוריו תוכן הקשור לתמונה שבו המשתמשים מתעניינים. אבל אם המשתמש רכש באתר מוצר זו אינדיקציה מאוד ברורה במה הוא מתעניין. אמזון יכולה להסיק מסקנות טובות מקניה ויוטיוב יכול להסיק מסקנות בזמן הצפייה של המשתמש.
ארכיטקטורה נפוצה היא ה TOP-N – בו המערכת מצליחה לזהות את N פריטים (לדוגמה N=10) שהמשתמש הכי מתעניין בהם.
ארכיטקטורה כללית
בתמונה הבאה מוצגת ארכיטקטורה כללית וכעת אסביר כל יחידה ושילובה בתהליך הכללי:

- Individual interests – בסיס נתונים עם מידע על ההתעניינות האישית של כל משתמש לדוגמא מידע על קישורים שנלחצו, פריטים שנקנו או סרטים שנצפו.
בסיסי הנתונים בעולם האמיתי יהיו לדוגמא mongodb, קסנדרה או Memcached. בסיסי נתונים אלו מספקים כמות נתונים גדולה בשאילתות פשוטות, באופן אידיאלי הנתונים מנורמלים באמצעות טכניקות כמו mean centering או z-scores כדי להבטיח שהנתונים דומים בין המשתמשים אבל בעולם האמיתי לעיתים קרובות הנתונים שלנו דלילים מכדי לנרמל אותם ביעילות.
- candidate generation – בתהליך אנו רוצים לייצר מועמדים להמלצה, פריטים שלדעתנו עשויים להיות מעניינים עבור המשתמש בהתבסס על התנהגותו בעבר, כך שבשלב ייצור המועמדים, לוקחים את כל הפריטים שהמשתמש ראה בהם עניין בעבר ואז עם מאגר נתונים אחר item similarities להתייעץ בהתבסס על התנהגות מצטברת.
דוגמה:
נניח ואני ממליץ עבורך המלצות. אני יכול להתייעץ עם מסד הנתונים של תחומי העניין האישיים ולראות שאהבת דברים הקשורים למסע בין כוכבים בעבר, ובהתבסס על ההתנהגות של משתמשים אחרים, אני יודע שאנשים שאהבו את מסע בין כוכבים, אוהבים גם את מלחמת הכוכבים, ולכן על סמך התעניינות שלך במסע בין כוכבים, אתה עשוי לקבל מועמדים להמלצה הכוללים פריטים של מלחמת הכוכבים.
בתהליך בניית המלצות אלה, אוכל להקצות ציונים לכל מועמד על סמך האופן בו דירגתי את הפריטים וכמה הדמיון חזק בין הפריט למועמדים שהגיעו מהם.
אני יכול אפילו לסנן מועמדים בשלב זה אם הציון הדמיון לא מספיק גבוה.
- בשלב הבא נעבור לדירוג מועמדים – candidate ranking.
ישנם מועמדים שיופיע יותר מפעם אחת והם יהיו צריכים להיות מאוחדים יחד בדרך כלשהיא, אולי ע”י שיפור הדירוג שלהם בתהליך, כדי שלא יעלו שוב ושוב.
לאחר מכן יש למיין את המועמדים להמלצה המתקבלת לפי דירוגים, כדי לקבל את רשימת ההמלצות.
ייתכן שלשלב הדירוג יש גישה למידע נוסף על מועמדי ההמלצות שהוא יכול להשתמש בהם, כגון ציוני סקירה ממוצעים, שניתן להשתמש בהם כדי לשפר את התוצאות עבור הפריטים המדורגים או הפופולריים במיוחד.
- שלב הסינון – Filtering – יהיה צורך בסינון כלשהו לפני הצגת רשימת המועמדים הסופית המומלצת למשתמש.
- שלב הסינון הוא המקום בו אנו עשויים לוותר על המלצות פריטים שהמשתמש כבר דירג, מכיוון שאיננו רוצים להמליץ על פריטים שהמשתמש כבר ראה.
- אנו עשויים להחיל כאן רשימת עצירה (stop list) כדי להסיר פריטים שיכולים להעליב את המשתמש או להסיר פריטים שנמצאים מתחת לציון איכות או סף מינימלי מסויים.
- זה המקום בו אנו מיישמים את מספר ההמלצות, N המלצות, הכי רלוונטיות למשתמש לדוגמה 10 ההמלצות הכי רלוונטיות.
- הפלט למשתמש (אזור תצוגת הסרטים למטה בתמונה) – הפלט משלב הסינון עובר לשלב תצוגת המשתמש, על ידי יישומון וכו’.
הדיאגרמה הזו היא גרסה מפוענחת של מה שמכנים סינון שיתופי מבוסס פריטים (item-based collaborative filtering). החלק הקשה הוא בניית הדמיון בין הפריטים.
ארכיטקטורה נוספת פופולרית היא לבנות בסיס נתונים לפני הדירוג החיזוי של כל פריט ע”י כל משתמש.
הערכה – אימון \ מבחן בדיקה ואימות צולב
Evaluating – Train/Test and cross-validation
אימון ומבחן
מתודולוגיה לבדיקת מערכות ממליצים באופן לא מקוון שהיא מבוססת על הרעיון של חלוקת הנתונים לאימון ומבחן.
מערכת ממליצה היא מערכת למידת מכונה, אתה מאמן אותה באמצעות התנהגות קודמת של משתמשים ואז אתה משתמש בה כדי לחזות פריטים שמשתמשים חדשים עשויים לאהוב.
ניתן להעריך מערכת ממליצים באופן לא מקוון כמו כל מערכת של למידת מכונה.
תהליך עם נתוני אימון ומבחן
- אתה מודד את המערכת לחזות כיצד אנשים דירגו דברים בעבר, כדי לשמור על כנות המדידה, אתה מפצל את נתוני הדירוג שלך לאימון ומבחן. כשקבוצת נתוני האימון היא בערך כ 80% מכלל הנתונים שלך.
- הכשרת מערכת הממליצים שלך תעשה רק באמצעות שימוש נתוני האימון.
זה המקום בו היא לומדת את מערכות היחסים הדרושות לה בין פריטים או משתמשים.
- לאחר האימון, אתה יכול לבקש ממנו לבצע תחזיות לגבי איך משתמש חדש עשוי לדרג פריט שהוא מעולם לא ראה. זה נעשה ע”י נתוני המבחן שהמערכת מעולם לא ראתה.
אז נניח שדירוג אחד במערך הבדיקה שלנו אומר שהמשתמש אכן דירג את הסרט למעלה מחמישה כוכבים, אנחנו שואלים את מערכת הממליצים איך היא חושבת שהמשתמש היה מדרג את הסרט מבלי לומר לה את התשובה ואז נוכל למדוד את דיוק המערכת אל מול הדירוג האמיתי.
לאחר שעוברים על כל קבוצת נתוני אימון בהנחה שיש לנו מספיק דוגמאות, אפשר בסופו של דבר לקבל מספר דיוק משמעותי שיגיד לך כמה המערכת הממליצים שלך טובה להמליץ על דברים, או ליתר דיוק, להמליץ על דברים שאנשים כבר צפו ודירגו, זה מה שניתן לעשות במערכת שלא ב liv.
k-fold cross-validation -תהליך אימות צולב
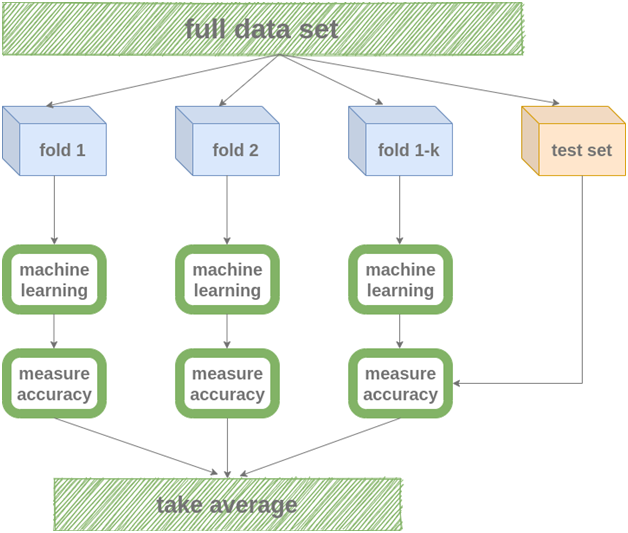
ניתן לשפר את שיטת פיצול נתונים של אימון ומבחן ע”י שיטת k-fold cross-validation.
רעיון השיטה דומה אך במקום מערכת אימון יחידה אנו יוצרים מערכי אימונים שהוקצו באופן אקראי. כל קבוצת נתוני אימון פרטני, או חתיכה (Fold) נתוני אימון מכלל דוגמאות נתוני האימון הכללי, משמש את מערכת הממליצים לאימון בלתי תלוי, עצמאי, ואז אנו מודדים את הדיוק של הfold ים המתקבלים אל מול מערך הבדיקות שלנו.
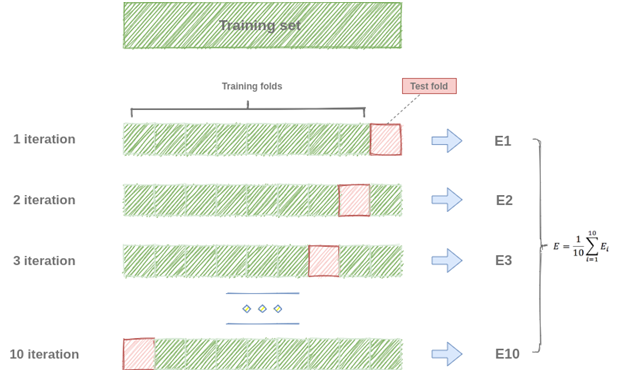
בסופו של דבר ערך הדיוק של כל fold מנבא את דירוג המשתמשים, אותם נוכל למצע ביחד.
- החיסרון זה יותר כוח חישוב
- היתרון שאתה נמנע מ overfitting אל מול קבוצה בודדת של נתוני אימון.
מסקנה, מטרת מערכת המלצות
אימון ,בדיקה ותיקוף צולב, הם דרכים למדוד את הדיוק של מערכת הממליצים שלך, כלומר, כמה מדויק אתה יכול לחזות כיצד המשתמש דירג את הסרטים שכבר ראה וסיפק דירוג עבורם, אבל זה לא הנקודה של מערכת הממליצים ואנו רוצים להמליץ למשתמשים על פריטים חדשים שהם לא ראו אך ימצאו בעיניהם מעניינים. וזה לא ניתן לעשות באופן בלתי מקוון.
סקירת מדדי הדיוק של מערכת ממליצים
- mean absolute error – MAE – שגיאה ממוצעת בערך מוחלט
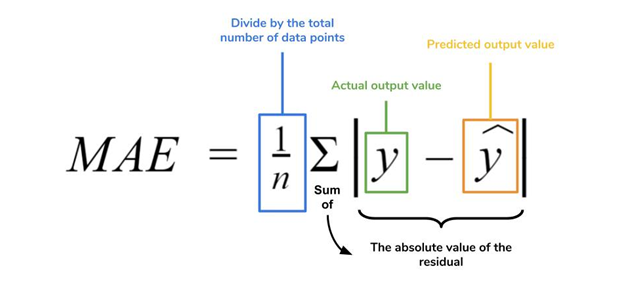
התמונה מ https://www.dataquest.io/blog/understanding-regression-error-metrics/
בהנחה שיש לנו דירוגים במערך המבחן שלנו, עבור כל דירוג, אנו יכולים לבדוק את הדירוג שהמערכת שלנו חוזה, y, והדירוג שהמשתמש נתן בפועל ,x. אנו לוקחים את ההפרש ביניהם בערך מוחלט כדי למדוד את השגיאה החיזוי של הדירוג. אנחנו מסכמים את כל הפרשי הדירוגים בדוגמאות שלנו בערך מוחלט ומחלקים במספר הדוגמאות שלנו n, וזאת כדי לקבל את גודל השגיאה הממוצעת של המערכת. ככל שנשאף לשגיאה נמוכה, המערכת תמליץ המלצות מדויקות שיותר קולעות לתחומי העניין של המשתמש.
- שגיאה ממוצעת בשורש הריבועי, root mean square error- RMSE

התמונה מ https://medium.com/analytics-vidhya/calculating-accuracy-of-an-ml-model-8ae7894802e
מדד זה מעניש כאשר החיזוי רחוק מהתוצאה האמיתית ומעניש פחות כשאתה קרוב בחיזוי מהתוצאה האמיתית.
ההבדל בינו לבין MAE הוא שבמקום לסכם את הערכים המוחלטים של כל שגיאת חיזוי, נסכם במקום זה את הריבועים של שגיאת החיזוי. תפיסת עלייה בריבוע מבטיחה לנו שנסיים עם ערכים חיוביים בדומה לערכים המוחלטים וגם היא מנפחת את העונש על טעויות גדולות יותר.
בסופו של דבר אנחנו מבצעים את פעולת השורש על התוצאה כדי להחזיר את השגיאה למספר הגיוני. גם פה נשאף לשגיאה נמוכה.
מדדי דיוק אלה לא באמת מודדים את מה שהמערכות הממליצות אמורות לעשות.
מכוון פחות אכפת לנו שמערכת ההמלצות דייקה לנו בדירוג משתמש שכבר ראה ודירג
ואכפת לנו בעיקר ממה שהמערכת חושבת על הסרטים הטובים ביותר שהמשתמש עוד לא ראה וזו בעיה שונה.
מה שחשוב הוא אילו סרטים אתה מציב בפני המשתמש ברשימת ההמלצות וכיצד הוא הגיב למה שהוא רואה באותה רשימה.
מדדי דיוק לרשימת המלצות עליונות
- hit rate , אחוזי הצלחה – מדידת דיוק של רשימות עליונות ( TOP N ) עבור משתמשים בודדים.
התהליך קורה כאשר המערכת מייצרת המלצות עליונות לכל המשתמשים במערך הבדיקה שלה. אם דירוג בפועל של המשתמש נמצאה ברשימת המלצות עליונות שלו נחשיב את זה כ HIT (הצלחה).
זה אומר שהמערכת למעשה מצליחה להראות למשתמשים דברים מספיק מעניינים שהם הצליחו לצפות בהם בעצמם, ולכן אנו רואים זאת כהצלחה.
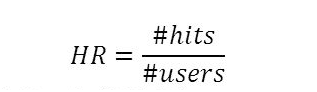
התמונה מ https://slideplayer.com/slide/9347453/
הסבר המשוואה שבתמונה שמעלינו – אוספים את כל ה hits (ההצלחות) בהמלצות העליונות של כל משתמש במערך הבדיקה ואת הערך האקראי הזה מחלקים במספר המשתמשים, התוצאה מייצגת את אחוזי ההצלחה.
לעומת בדיקת דיוק כמו MSE ו RMSE שאיתם מדדנו את דיוק הדירוג האישי של המשתמשים, פה אנו מודדים את דיוק הרשימות הראשוניות top n עבור משתמשים בודדים.
בעזרת שיטת leave-one-out cross-validation אנו נבצע את המדידה, אז כמו שאמרתי במדידה זו מחשבים את ההמלצות העליונות עבור כל משתמש בנתוני האימון שלנו אבל אנחנו נסיר בכוונה אחד מאותם פריטים מנתוני האימון מכל משתמש למען מערך נתוני המבחן, שיטה זו נקראת leave-one-out.
לאחר סיום האימון אנו בודקים את יכולת מערכת הממליצים שלנו להמליץ בעזרת פריט שהושאר בחוץ.
החיסרון שבזמן הבדיקה נורא קשה לקלוע לסרט אחד מתוך רשימה של סרטים אלה אם יש לך כמות גדולה ממש של נתונים, לכן סוג כזה של חישוב מאוד קשה למדידה.
- ARHR – average reciprocal hit rate – השפעה ממוצעת על אחוזי ההצלחה.
הוא מאוד דומה ל hit rate אך המדד ARHR מציג היכן נמצא המיקום של הפריט ברשימת הפריטים העליונים (top n) של המשתמש:
התמונה מ https://medium.com/@arthurlee_73761/recsys-16-local-item-item-models-for-top-n-recommendation-753555b5c1c
זה אומר שכאשר המערכת מצליחה להמליץ על פריטים עליונים יותר ברשימה זו נחשבת ל HIT מאשר
המלצה על מיקום פריטים נמוכים יותר מרשימת המומלצים.
ההבדל היחיד הוא שבמקום לסכם את ההצלחות, אנו מסכמים אם הצלחנו לחזות את המיקום ההדדי ברשימה של כל הצלחה.
כדוגמת הטבלה התחתונה שלפנינו נראה שאם אנו חוזים בהצלחה המלצה במקום שלוש זה נחשב לשליש. אבל ההצלחה במקום הראשון ברשימה יקבל את המשקל המלא של 1.0
| Reciprocal rank |
Rank |
| 1/3 |
3 |
| 1/2 |
2 |
| 1 |
1 |
וכך אנו “מענישים” יותר את מה שאנחנו פחות רוצים להמליץ.
- cumulative hit rank – cHR – הצטברות של אחוזי הצלחה
הרעיון הוא שאנחנו משליכים ההצלחות כאשר חיזוי הדירוג נמצא מתחת לסף כלשהו.
הכוונה שאסור להכניס לרשימה הממליצה פריטים שאנו חושבים שהמשתמש לא יהנה מהם.
בטבלה הבאה אנו רואים דוגמה טובה למקרה זה, שאומר שאם ערך הסף שלנו הוא שלושה כוכבים אז לא היינו מוסיפים לרשימת ההמלצות את הפריטים שבשורות שתיים וארבע. הכוונה אנו נסיר המלצות חזויות שהחיזוי שלהם הוא שלושה כוכבים ומטה בהנחה שאנו יודעים שהמשתמש לא יהנה מאותם המלצות.
| Predicted Rating |
Hit Rank |
| 5.0 |
4 |
| 3.0 |
2 |
| 5.0 |
1 |
| 2.0 |
10 |
- Rating hit rate – rHR – שיעור צפיות בדירוג
כאן אנו מסתכלים על קצב ההתאמה (hit rate) אנו מחשבים את ציון הדירוג עבור כל דירוג כדי למצוא איזה סוג דירוג מקבל יותר צפיות. אנו מסכמים את מספר ההצלחות עבור כל סוג של דירוג ברשימת ה- Top-N שלנו ומחלקים את המספר הכולל של הסרטים מכל דירוג ברשימת ה- Top-N שלנו.
מסתבר ששיפורים קטנים ב- RMSE יכולים למעשה לגרום לשיפורים גדולים בשיעורי ההתאמה, אבל מסתבר שאפשר לבנות גם מערכות ממליצות עם שיעורי המלצות מוצלחות למשתמש, אך ציוני RMSE גרועים. אז RMSE ושיעור ההתאמה לא תמיד קשורים זה לזה.
ישנם מדדים נוספים למערכות ממליצות מלבד אחוזי דיוק הצלחה,
מדדים להערכת תפקוד מערכת המלצות
- Coverage – זהו מדד הכיסוי המודד את אחוז ההמלצות האפשריות שהמערכת מסוגלת לספק.
לדוגמה אם יש לנו מערך נתונים של סרטים, שרובם לא מדורגים מערכת ההמלצות לא תצליח ללמוד עליהם ועל כן לא תמליץ על אותם סרטים מחוסרי דירוג, לכן הכיסוי של המערכת ייחשב כנמוך.
כיסוי המערכת לא מגיע בקנה נגדי אל מול הדיוק של המערכת, ז”א שאם החלטת שיש סף איכות מסויים של ההמלצות ייתכן שתשפר את הדיוק שלך אבל הכיסוי שלך יקטן.
הכיסוי נותן לנו גם תחושה של כמה מהר פריטים חדשים בקטלוג שלך יתחילו להופיע בהמלצות.
לדוגמא כאשר יש מוצר חדש באייבי, הוא לא יופיע בהמלצות עד שכמה אנשים יקנו אותו פעולה הקנייה שלהם תיצור דפוס חיובי לגבי המוצר בנוסף לרכישת פריטים אחרים של אותם לקוחות. עד שנוצרים הדפוסים האלה הוספת הפריט החדש הזה יפחית את מדד הכיסוי של אייבי.
- Diversity – זהו מדד הגיוון המודד את אחוז הפריטים השונים זה מזה שיש ברשימת ההמלצות של המשתמש.
דוגמא למגוון נמוך יכול להיות הספרים הבאים בסדרה של ספר שהמשתמש קורא ולא ספרים שונים הקשורים לספר הקריאה שלו.
מערכות ממליצות רבות מתחילות בחישוב מדד דמיון כלשהו בין פריטים, כך שניתן להשתמש
בערכי הדמיון האלו כדי למדוד את הגיוון.
S = avg similarity between recommendation pairs

אם נסתכל על הדמיון בין כל זוג פריטים ברשימת ההמלצות העליונות שלנו נוכל להפעיל עליהם את פעולת הממוצע כדי להבין עד כמה הפריטים ברשימה הם דומים, כמו שרואים בתמונה ,שבתחילת מושג זה, ניתן לקרוא למדד הזה S וכדי לקבל את הגיוון אנחנו נחסיר 1 בתוצאת ה S כדי לקבל את ערך הגיוון.
ציון גבוה מדי של גיוון יכול להעיד על המלצה של פריטים אקראיים לחלוטין ופירוש המלצות אלו הם ממש לא במלצות טובות, לכן תמיד צריך להסתכל על מדד המגוון לצד מדדים המודדים את איכות ההמלצות גם כן.
- Novelty – מדד ממוצע לפופולריות של פריטים ברשימת ההמלצות העליונות.
במערכת הממליצים יש מושג של אמון משתמשים, משתמשים רוצים לראות פחות פריטים מוכרים ברשימת המלצות שלהם שגורמים להם לומר שזו המלצה טובה עבורם. אם נמליץ כל הזמן פריטים שאנשים לעולם לא שמעו עליהם, המשתמשים עשויים להסיק שהמערכת לא באמת מכירה אותם.
כמו כן, פריטים פופולריים מתאימים לחלק גדול מהאוכלוסיה ולכן אנו מצפים שפריטים אלו יתאימו גם למשתמשים שלעולם לא שמעו עליהם, לכן אם המערכת לא ממליצה על פריטים פופולריים צריך לבדוק אם המערכת באמת עובדת.
מסקנה, יש ליצור איזון בין פריטים פופולריים לבין מה שאנו מכנים גילוי מוחלט של פריטים חדשים שהמשתמש לא שמע עליהם מעולם.
מצד אחד הפריטים מוכרים מייצרים אמון עם המשתמש ופריטים החדשים מאפשרים למשתמש לגלות דברים חדשים שהוא עשוי לאהוב.
איך תיאוריית הזנב הארוך מתקשרת למערכת המלצות?
מטרת מערכת המלצות היא פריטי השירות מה שנקרא תאוריית הזנב הארוך.
לפי ויקיפדיה:
תאוריית הזנב הארוך (The Long Tail) הוא ביטוי בתחום הסטטיסטיקה שטבע כריס אנדרסון לתיאור תופעות כלכליות ותרבותיות הבאות לידי ביטוי במיוחד בערוצי שיווק מתקדמים כגון האינטרנט והטלוויזיה הדיגיטלית.
אנדרסון טוען כי עיקר ההצלחה של חברות כמו אמזון ונטפליקס היא לא ממכירה של מספר מוגבל של הצלחות כמו בחנויות המסורתיות, אלא ממספר עצום של פריטים בעלי פופולריות נמוכה. לפי טענה זו, כשנותנים לבני האדם את חופש הבחירה התרבותית, הטעם שלהם יותר מגוון מאשר כל מגוון שמוגבל במגבלות פיזיות. חברות שיספקו את חופש הבחירה הזה ירוויחו יותר מאשר חברות שיספקו מספר מצומצם של הצלחות. הרווח של החברות יבוא לידי ביטוי במכירות מרובות של פריטים פחות פופולריים באופן מצטבר. לפיכך, סך הרווח מהמכירה של הפריטים הלא פופולריים, יעלה על הפריטים הפופולריים שנחשבים “רבי מכר”.
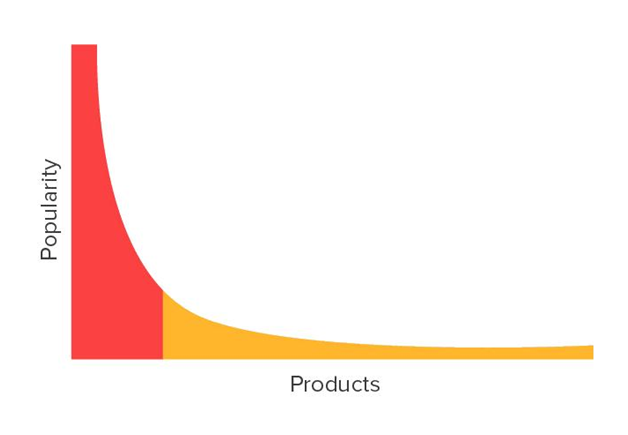
לפי הגרף, בזנב הארוך ציר ה Y הוא מספר המכירות או הפופולריות, וציר ה X מייצג את המוצרים.
מה שאפשר להסיק שרוב המכירות מגיעות ממספר מאוד קטן של פריטים, אך יחד עם זאת, הזנב הארוך מהווה כמות גדולה של מכירות גם כן.
החלק הצהוב בגרף מציין את פריטים המסופקים לאנשים עם תחומי עניין נישה ייחודיים.
אנו יכולים להסיק מגרף הזנב הארוך, שמערכת המלצות יכולה לעזור למשתמשים לגלות את אותם פריטים בזנב הארוך הרלוונטיים לתחומי העניין הייחודיים שלהם.
- Churn rate – מדד קצב הנטישה
מדד קצב הנטישה יכול למדוד עד כמה המערכת רגישה להתנהגות חדשה של משתמש, זאת אומרת אם משתמש מדרג סרט חדש, האם זה משנה באופן מהותי את ההמלצות שניתנו לו? אם התשובה היא כן, אז הציון יהיה גבוה.
אם המערכת המליצה למשתמש על פריט למשך זמן רב אך הוא לא לוחץ עליה, אז בשלב מסויים עליה פשוט להפסיק לנסות להמליץ על אותו פריט ולהראות לו משהו אחר? לפעמים קצת אקראיות בהמלצות העליונות יכולות לגרום להם להראות רעננים ולחשוף את המשתמש לפריטים רבים שלא ידע על קיומם ללא המערכת, אבל נטייה גבוה כמו גיוון וחידוש מדד גבוה של קצה הנטישה אינו דבר טוב.
כאשר המערכת מבינה את האיזון בין כל המדדים יחד היא תוכל להעניק רשימות ממליצות טובות יותר.
- Responsiveness – מדד היענות.
מודד באיזו מהירות משפיעה התנהגות המשתמש על רשימת ההמלצות.
לדוגמא אם משתמש מדרג סרט חדש, האם יש השפעה מיידית על רשימת ההמלצות שלו או ההשפעה תראה רק למחרת?, נגיד אחרי ריצה של עבודה לילית על השרתים אשר מעדכנים את התוכנה עם רשימת ההמלצות החדשות.
מערכות ממליצות בעלות היענות מיידית הן מורכבות, קשות לתחזוקה ויקרות לבנייה, לכן יש לאזן את המערכת בין היענות לפשטות.
ישנם מערכות ממליצות בין לאומיות שאמורות לקחת בחשבון ברשימת ההמלצות את הבדלי תרבויות, יש כאלו שיאהבו גיוון בהמלצות מאשר אחרות שיעדיפו אחת לשבוע, ישנם גם הבדלים בטראנדים שונים וכו’ ולכן לא תמיד המדדים שדיברנו עליהם יוכלו לתת תמונת מצב מלאה על המערכת.
- בדיקות A/B באופן מקוון, כדי לכוון את מערכת הממליצים.
זאת עושים ע”י הצבת המלצות מאלגוריתמים שונים מול קבוצות שונות ולמדוד אם אכן קונים, צופים או אפילו מדרגים את ההמלצות שהומלצו להם ברשימה.
בדיקות ה A/B הוא מדד מצויין כדי להבין מה קורה בעולם האמיתי ואפילו יכולת לתת מסקנות אשר יכולות להוריד את מידת המורכבות של המערכת.
אז זכרו כל המדדים שדיברנו יכולים לתת מסקנה על בדיקת המערכת באופן לא מקוון כאשר מפתחים את המערכת, אבל גם אז אם המדדים שלנו טובים לא ניתן להכריז על המערכת כמערכת מנצחת לפני שבודקים אותה בעולם האמיתי ושם למדוד עד כמה היא משפיעה על המשתמשים החדשים.
By David Kohav
Linkedin: https://www.linkedin.com/in/davidkochav/
GitHub: https://github.com/DavidKohav/recommender-systems