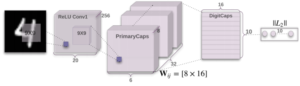
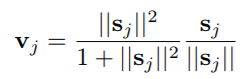בכתבה זו מטרתי להסביר את התיאוריה שבמאמר “Dynamic Routing between Capsules”. למי שלא מכיר את ההקשר ממליץ לקרוא קודם את הרקע בכתבה הזו: “הרעיון מאחורי רשת הקפסולות” שמסבירה את המאמר המוקדם יותר של הינטון: “Transforming Auto-“encoders. (אם כי אפשר להבין גם הכול מכתבה זו בלבד)
נציין שעל אף שהרעיון מעניין ונשמע מבטיח, הוא בינתיים הוכח כמנצח רק על מאגר תמונות ספרות וגם על ספרות חופפות מ MNIST. (ז”א תמונה המכילה כמה ספרות זו על זו). יתרון משמעותי נוסף שיש לארכיטקטורה זו היא ההסתפקות ב database קטן, וחסרון הוא משך אימון ארוך.
תיאוריה
אם עלי לתת את כל התורה על רגל אחת אגיד על דרך המשל:
על ההורים לקבל החלטות כבדות משקל בחיים ועל הילדים לקבל החלטות פשוטות. כל הורה מקבל את החלטותיו לפי דעת הרוב של ילדיו, כאשר כל ילד “מומחה” בנישה קטנה אחרת. ההורים למשל עשויים להחליט לעבור למושב אחרי שראו ששנים משלושת ילדיהם אוהבים טבע.
ולהקשר הזיהוי תמונה: אוביקט בתמונה מורכב מהרבה אלמנטים. זיהוי של כל אלמנט ומאפייניו (למשל גודלו ומיקומו היחסי) יכול להעיד על קיום האוביקט כולו בתמונה.
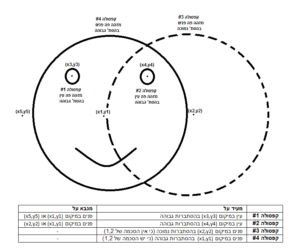
האוביקט בתמונה מיוצג במבנה עץ שכל קודקוד הוא קפסולה שיש לו בנים ואב. שכבה של קפסולות הינן קפסולות מאותו הדור. כל קפסולת בן מנבאת מה תגיד קפסולת אביו. למשל בתמונת פנים קפסולה שמזהה אלמנט עין שאביה הינו קפסולה המזהה אלמנט פנים, תעיד על פנים במיקום זה או אחר בהסתברויות גבוהות. הסכמה בין קפסולות מאותה שכבה לגבי דיעת האב תכריע את דיעת האב. אמחיש את הרעיון באיור הבא:
capsules demo
איור זה מדגים זיהוי פנים עם שתי שכבות קפסולות. שכבה של קפסולות שמיומנות בלזהות עיניים ושכבה גבוהה יותר של קפסולות שמיומנות בלזהות פנים. ניתן להמשיך את הדוגמה הזו עם עוד שכבות: למשל שכבה נמוכה יותר של קפסולות שמיומנות בלזהות עיגולים והן תעזורנה לקפסולות שמזהות עיניים. או שכבה עליונה יותר שמיומנת בלזהות אנשים ונעזרת בשכבה שמתחתיה שמיומנת בלזהות פנים.
אגב, אחד היתרונות של שיטה זו היא בזיהוי אוביקטים חופפים וזאת כי אז יש צורך בהסכמה הדדית בין כל הקפסולות כדי להחליט מהו האוביקט\ים הכולל שרואים בתמונה.
אז מהן בדיוק קפסולות ?
קפסולות הם יחידות אבסטרקטיות (בהמשך, בחלק הפרקטי נראה מימוש) שמקבלות וקטורים ומחזירות וקטורים.
כל קפסולה מחזירה:
1. וקטור מוצא שלה (*) – שגודלו מעיד על ההסתברות לקיומו של האלמנט וכיוונו מקודד את המאפיינים שלו.
2. וקטורי פרדיקציה בעבור כל אחת מהקפסולות בשכבה הבאה.
המשמעות של וקטורי הפרדיקציה הינם: מה לדעת קפסולה i יהיה המוצא של קפסולה j. אם נניח קפסולה i מומחית בזיהוי עיגולים ומזהה בהסתברות גבוהה עיגול בקורדינאטה (x3,y3) בתמונה, אז תנבא שקפסולה משכבה גבוהה ממנה שאחראית על זיהוי פנים תוציא כפלט פנים במיקום (x1,y1) .
כל קפסולה מקבלת:
1. וקטורי פרדיקציה מכל אחת מהקפסולות שבשכבה שלפניה. אם אין שכבה מלפניה (כי זו השכבה הראשונה) אז מקבלת קלט כלשהוא, למשל במימוש המוצע כפי שנראה בהמשך מקבלת תוצאה של שכבת קונבולוציה. (פיצ’רים של התמונה המקורית)
(*) – וקטור תוצאה של קפסולה הינו שיקלול חכם ומנורמל של וקטורי הפרדיקציה מכל הקפסולות בשכבה שלפניה. השיקלול הזה מתואר באלגוריתם Dynamic Routing.
מהו אלגוריתם Dynamic Routing
וקטור מוצא של קפסולה הינו סכום משוקלל של וקטורי הפרדיקציה שהגיעו מהקפסולות שבשכבה הקודמת.
השיקלול ממומש באמצעות אלגוריתם Dynamic Routing ומהותו עידכון המשקלים\מקדמי צימוד (של כל אחד מאותם וקטורי פרדיקציה) באופן איטרטיבי לפי מידת ה-“הסכמה” בין וקטור פרדיקציה כלשהוא לבין וקטור התוצאה (כפי שהוא באיטרציה הנוכחית). ככל שוקטור פרדיקציה כלשהוא תואם לכיוון של וקטור התוצאה כך יגדל המקדם\המשקל שלו. מידת התאימות מחושבת ע”י מכפלה סקלרית בינהם. (הרי מכפלה סקלרית בין וקטורים בעלי אותו כיוון הינה 1 ואחרת אם הם בכיוונים שונים פחות מ-1)
תיאור האלגוריתם בין שכבת קפסולות l לבין השכבה הבאה l+1 בעבור r איטרציות ניתוב (routing):
קלט: וקטורי הפרדיקציה של כל אחת מקפסולות i מהשכבה l לכל אחת מהקפסולות j בשכבה l+1:
פלט: וקטור המוצא של כל קפסולה j משכבה l+1 :
האלגוריתם:
בהתחלה אפס את כל מקדמי הצימוד
בצע r איטרציות את שתי הפעולות הבאות: (שיקלול וקטור מוצא + עידכון משקלים)
1.
כאשר מקדמי הצימוד בין הקפסולות מנורמלים באופן הבא:
2. עדכן את מקדמי הצימוד לפי מידת ההסכמה (המכפלה הסקלרית) בין וקטורי הפרדיקציה לוקטור התוצאה:
סוף!
כעת אם ברצונך להבין את פרטי המימוש ואת הארכיטקטורה המוצעת במאמר, עבור לכתבה:
“העמקה לרשת הקפסולות Dynamic Routing Between Capsules – פרקטיקה“