
הגדרה
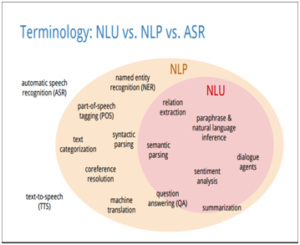
“הבנת שפה טבעית” היא תת תחום של “עיבוד שפה טבעית”, הנכלל במסגרת תחום הבינה המלאכותית. התחום נחשב לאחד האתגרים הקשים של הבינה המלאכותית.
המשימה העיקרית של “הבנת שפה טבעית” היא לייצר מערכות המסוגלות ל”קרוא” ול”הבין” טקסט של שפה מדוברת באיכות שאנשים מסוגלים. התחום כולל משימות מגוונות, למשל “מענה על שאלות (Question Answering)”,”סיכום מסמכים (Text Summarization)”, “תרגום מכונה (Machine Translation)”.התחום קשור באופן עמוק למספר רב של יישומים, למשל, בוטים ועוזרים חכמים (סירי, אלקסה וכו’).
https://labs.eleks.com/2018/02/how-to-build-nlp-engine-that-wont-screw-up.html
קצת היסטוריה
במהלך שנות ה-50 של המאה הקודמת נערכו הניסיונות הראשונים להתמודד עם אתגרי השפה הטבעית, למשל, ניסוי של תרגום אוטומטי של כשישים משפטים מרוסית לאנגלית. מבצעי הניסוי טענו כי בתוך שלוש עד חמש שנים, תרגום מכונה יהיה בעיה פתורה. בשנים אלו הוגדרו מטרות שאפתניות של יצירת מערכות ממוחשבות המסוגלות לתקשר עם בני אדם בשפה טבעית,בדומה לאופן שבו בני אדם מתקשרים. ההערכה הרווחת היתה שבתוך 2 עד 3 עשורים מטרות אלו יושגו.
בשנות ה-60 נעשו ניסויים שהתבססו על מציאת תבניות (Pattern matching) באמצעות קבוצות קטנות של חוקים, למשל ELIZA.
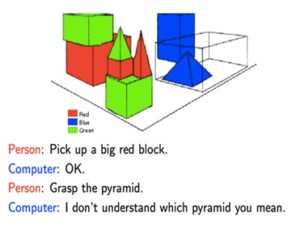
בשנות ה-70 וה-80 פותחו מערכות עשירות מבחינה בלשנית, מבוססות לוגיקה, שפעלו בתחומים מוגבלים. דוגמא למערכת שכזו היתהSHRDLU , תוכנה שפותחה על ידי טרי וינוגרד ופעלה בתחום מצומצם של קוביות משחק. SHRDLU בצעה פקודות וענתה על שאלות באמצעות דיאלוג אינטראקטיבי בשפה האנגלית.
תודה ל https://www.topbots.com/4-different-approaches-natural-language-processing-understanding/
SHRDLUנתפסה כסימן לכך שתחום הבינה המלאכותית מתקדם באופן משמעותי, אבל היתה זאת רק אשליה: כאשר וינוגרד ניסה להרחיב את עולם קוביות המשחק לתוכנית מקיפה יותר, המורכבות התחבירית וכמות החוקים היו בלתי ניתנים לניהול. כמה שנים לאחר מכן, וינוגרד פרש מהפרויקט.
בשנות ה-90 החלה המהפכה הסטטיסטית בתחום עיבוד השפה שהובילה לירידה בניסיונות לייצר מערכות להבנה איכותית של שפה טבעית.
ההתפתחות הטכנולוגית בעשור האחרון הולידה מספר יישומים, דוגמת סירי, ווטסון ואלקסה, המאפשרים לבני אדם לתקשר עם המחשב בשפה טבעית ולבצע משימות פשוטות יחסית. עם זאת, לפי חוקרים שונים (ג’ון סווה, ג’ון גיאננדראה), עדיין אין כיום מערכות מחשב המסוגלת ללמוד ולהבין שפה באיכות שילד קטן יכול.
מורכבות הבנת שפה טבעית
הבנת שפה טבעית ברמה הדומה להבנה אנושית עדיין רחוקה לדעתם של חוקרים רבים, בשל המורכבות הרבה של השפה. הבנת שפה כוללת התמודדות עם מספר רב של אתגרים:
- למילים רבות יש מספר משמעויות, נדרשת יכולת לבחור את המשמעות הנכונה על מנת להבין משפט מסוים בצורה טובה.
- ניתן להביע את אותה כוונה במספר רב של משפטים שונים.
- למילה או למשפט יכולים להיות מספר משמעויות שונות בהקשרים שונים. השאלה “האם אני יכול לחתוך אותך?” פירושה דברים שונים מאוד אם אני עומד לידך בתור או אם אני מחזיק סכין.
- משפטים מכילים הנחות ואמונות נסתרות. למשל, המשפט “הפסקתי לאכול בשר” מצביע על ש”אכלתי בשר בעבר”. נדרש ידע מוקדם על מבנה השפה ועל העולם על מנת לייצר הבנה ברמה אנושית.
- תקשורת מילולית יכולה להכיל ביטויי סלנג, קיצורים, שגיאות כתיב, וכדומה.
גישות מחקריות
אחד המושגים המעניינים בתחום הבנת השפה הוא “ביסוס שפה (Language Grounding)”. בני האדם מבינים מילים רבות במונחים של אסוציאציות עם חוויות חושיות-מוטוריות. אנשים חייבים לקיים אינטראקציה פיזית עם העולם כדי להבין את המשמעות של מילים כמו “אדום”, “כבד” או “מעל”. ביסוס שפה מאפשר לבני אדם לרכוש ולהשתמש במילים ובמשפטים בהקשר נתון.
ניתן לסווג את הגישות השונות להבנת שפה למספר קטגוריות:
- סטטיסטיקה ולמידת מכונה
- ייצוג ידע מובנה
- המרת שפה לתוכניות הרצה
- לימוד שפה באופן אינטראקטיבי
סטטיסטיקה ולמידת מכונה
הגישה הסטטיסטית עושה שימוש בשיטות ההופכות תוכן טקסטואלי לווקטורים שלמילים ומבצעות ניתוח מתמטי של הווקטורים. גישה זו מאפשרת בניית מודלים ללא צורך בהגדרות ידניות של מומחי תוכן ושפה. הגישה אינה מסתמכת על הבנת המשמעות של מילים, אלא על למידת קשרים בין מילים שונות ובין משפטים שונים באמצעות מודלים מבוססי למידת מכונה.
בשנים האחרונות, עם התפתחות טכניקות למידה עמוקה, פורסמו מספר מודלים מבוססי למידה עמוקה הנקראים “מודלי שפה מאומנים מראש (Pre-Trained Language Models)” שמספקים תוצאות איכות במגוון משימות של הבנת שפה. מודלים אלו מאומנים מראש באמצעות קורפוסים, דוגמת ויקיפדיה, ועושים שימוש ביכולות העברת למידה (Transfer learning) כדי לאפשר התאמה קלה ומהירה של המודל למשימות הבנת שפה ספציפיות. המודלים המובילים במשפחה זו הם ULMFiT, ELMo ו BERT.
החיסרון העיקרי של הגישה הוא היותה חסרת ביסוס שפתי (אינה מקושרת למשמעות בעולם) ולכן,ככל הנראה, מוגבלת ביכולות ביצוע היסקים סמנטיים ופרגמטיים המבוססים על ידע עולם. במחקר שנערך לאחרונה, הודגמו תוצאות מרשימות של BERT לעומת ביצועי מודלים אחרים, במשימות מענה על שאלות הגיון כללי (Commonsense QA). יחד עם זאת, התוצאות של BERT רחוקות מאלו של בני אדם.
ייצוג ידע מובנה
גישה זו מסתמכת על הפקת משמעות של שפה באמצעות
- ייצוג ידע על העולם באופן מובנה
- מיפוי השפה אל מבני המידע
- ביצוע חישובים והיסקים על בסיס המידע המובנה
ישנן שיטות רבות לייצוג יידע באופן מובנה,למשל, אונטולוגיות (Ontologies), מסגרות (Frames), גרפיים מושגיים (Conceptual Graphs) ופורמטים מגוונים של ייצוג עובדות וחוקים לוגיים.
הדרך המקובלת להגדרת יידע מובנה היא שימוש באונטולוגיות. אונטולוגיה היא מודל היררכי פורמלי המכיל הגדרות של מושגים (Concepts), תכונות של מושגים, וקשרים בין מושגים. לדוגמא, המושג “פיצה” הוא בעל קשר של ירושה (“Is a”) למושג “מזון/אוכל” וקשר ‘has Topping’ למושג “תוספת”.

https://www.researchgate.net/publication/236842047_Efficient_Regression_Testing_of_Ontology-Driven_Systems
ניתן למצוא כיום ברשת אונטולוגיות רבות הכוללות מידע בתחומים שונים. ניתן לסווג אונטולוגיות לשתי קטגוריות עיקריות:
- אונטולוגיות עיליות ((Upper Level Ontologies – מכילות מושגים כלליים המשמשים תחומי ידע רבים, למשל SUMO
- אונטולוגיות התמחות (Domain Ontologies) – מכילות הגדרות שלמושגים בתחום ידע ספציפי, למשל אונטולוגיות בתחום הפארמה.
פרוייקט Cyc הוא דוגמא לניסיון ארוך שנים ליצירת מאגר ידע מובנה המקיף אזורים נרחבים של הידע האנושי. Cyc מציע יכולות מתקדמות של הבנת שפה, תוך שימוש במתודות לניתוח סמנטי ופרגמטי, ולא רק ניתוח תחבירי או סטטיסטי.
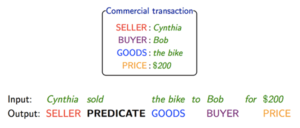
מודל מידע נוסף בו נעשה שימוש החל משנות ה-70 הוא המסגרות (Frames). מסגרת היא מבנה נתונים לייצוג מצב או תהליך טיפוסי, למשל מסגרת של “אירוע קנייה” מכילה מידע מובנה של “מוכר”, “קונה”, “סחורה” ו “מחיר”.
תודה ל https://www.topbots.com/4-different-approaches-natural-language-processing-understanding/
החיסרון של הגישה הוא המאמץ האנושי הגבוה הנדרש ליצירת ואכלוס מבני המידע, שכן, בתהליך נדרשת עבודה ידנית רבה. בתחומים מסוימים, מומחה תוכן חייב ליצור את המידע, דבר אשר מגביל את מרחב כיסוי הידע והעלויות הנדרשות.
המרת שפה לתוכניות הרצה
לפי גישה זו, השפה הטבעית מומרת לתוכניות מחשב ברות הרצה באמצעות תהליך של ניתוח סמנטי, שממפה ביטויים בשפה טבעית לייצוג פורמלי מובנה. הגישה משמשת ביצוע פקודות מורכבות בשפה טבעית בצורה אוטומטית, למשל, ביצוע הנחיות ניווט או שליפת וניתוח מידע מבסיסי נתונים.
כדי לענות על השאלה “מהי העיר בעלת האוכלוסייה הגדולה ביותר באירופה”, על המנתח הסמנטי להמיר את הקלט בשפה הטבעית לתוכנית הרצה שתבצע שאילתת חיפוש של ערים באירופה ותחזיר כתשובה את העיר בעלת כמות האוכלוסין הגבוהה ביותר.

תודה ל https://www.topbots.com/4-different-approaches-natural-language-processing-understanding/
הרכיב המרכזי בגישה זו הוא המנתח סמנטי (Semantic Parser) הממיר את השפה הטבעית לייצוג סמנטי, למשל,ביטויים לוגיים, ביטויים המייצגים משמעות בשפה פורמלית (meaning representations) או לתוכניות מחשב בשפות כמו SQL אוJAVA . לאחר שלב ההמרה,מתבצע שלב ההרצה במסגרת סביבה נתונה, למשל בסיס נתונים רלציוני, כדי להגיע אל התוצאה הרצויה, למשל מענה לשאלה.
המנתחים הסמנטיים המוקדמים היו מבוססי חוקים (Rule Based). בהמשך, הופיעו מנתחים סמנטיים שעשו שימוש בטכנולוגיות לימוד מכונה, כאשר הקלט לתהליך האימון הוא קורפוס של צמדי משפטים (אחד בשפה טבעית והשני בייצוג פורמלי).
הגישה מאפשרת סמנטיקה עשירה ועיבוד מקצה לקצה של פעולות מורכבות. החיסרון העיקרי של הגישה הוא שהיישומים מרוכזים בתחומים מצומצמים בשל הצורך בהגדרות ידניות אנושיות.
לימוד אינטראקטיבי
הבנת שפה טבעית באמצעות לימוד אינטראקטיבי היא גישה מחקרית התופסת תאוצה בשנים האחרונות. ההנחה בבסיס הגישה היא שהבנת שפה אמתית תגיע מלמידה של שילוב של מילים יחד עם ההשפעות שלהם על העולם.
פרופסור פרסי ליאנג (Percy Liang), מאוניברסיטת סטנפורד,תומך בגישה זו וגורס שפיתוח של סביבות למידה אינטראקטיביות בהן בני אדם מלמדים מחשבים לתקשר בשפה טבעית יוביל בהדרגה ליצירת מערכות מחשב שיוכלו לתקשר בשפה טבעית. על מנת לבחון זאת, הוא יצר משחק בשם SHRDLURN (כהוקרה ל SHRDLU של וינוגרד) הפועל בעולם של קוביות משחק. במשחק זה, אדם צריך להנחות את המחשב כיצד להעביר בלוקים מצד אחד אל הצד השני, כאשר המחשב מתחיל לפעול ללא מושג של שפה. צעד אחר צעד, האדם אומר משפט ואז מראה למחשב כיצד התוצאה של הפעולה צריכה להיראות. התוצאה המפתיעה שהניסוי הניב היא שניתן ללמד מחשב ל”הבין” כל שפה שהיא (בתחום המצומצם של עולם קוביות המשחק), אפילו שפה מומצאת, כל עוד ההנחיות הן קונסיסטנטיות.
לימוד שפה באופן אינטראקטיבי קשור באופן הדוק לתחום הפסיכולוגיה הקוגניטיבית ולמחקר של תהליכי רכישת שפה. גארי מרקוס, פרופסור לפסיכולוגיה התפתחותית מאוניברסיטת ניו-יורק (NYU), מגיע מרקע מחקרי של תהליכי רכישת שפה ומנסה להבין כיצד ילד בן שנתיים-שלוש מצליח ללמוד לדבר ולהבין את העולם. מרקוס טוען כי ישנם הרבה דברים שילדים אנושיים מצליחים לעשות ומכונות לא, למשל, היסקים ממידע מצומצם או לימוד שפות מורכבות. לדעתו, העמקת המחקר בתחום זה, יחד עם הבנה טובה יותר של אופן פעולת המוח האנושי, תביא ליצירת מודלים של למידה שיאפשרו התמודדות טובה יותר עם האתגרים של הבנת שפה טבעית.
לסיכום
הבנת שפה אנושית היא אתגר קשה ומורכב. בשנים האחרונות התחום מרכז עניין רב וניכרת התפתחות טכנולוגית, בעיקר בגישות המתבססות על למידה עמוקה. עם זאת, נכון לרגע זה לא קיימת מערכת מחשב המצליחה להתמודד עם אתגרי השפה בהצלחה המתקרבת לזו האנושית.
התפתחות ושילוב של הגישות המופיעות למעלה, לצד העמקת המחקר בתחומים של לימוד אינטראקטיבי ותהליכי רכישת שפה, יאפשרו בעתיד פיתוח מערכות המסוגלות לתקשר בשפה טבעית ביתר הצלחה.
קישורים
- 4 Approaches to Natural Language Processing & Understanding
- The Two Paths from Natural Language Processing to Artificial Intelligence
- What Every NLP Engineer Needs to Know About Pre-Trained Language Models
- How researchers are teaching AI to learn like a child
- ELIZA
- Learning Language Games through Interaction
- COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge
- Cycorp
אשמח לשמוע תגובות והערות לכתבה… בימים אלו אני פועל להקמת מיזם בתחום עיבוד שפה טבעית. אנשים שיש להם תשוקה לתחום ומעוניינים לקחת חלק במיזם מוזמנים לפנות אליי…
