בעל תארים ראשונים בהנדסת אלקטרוניקה ובמתמטיקה, ובעל תואר שני בהנדסת אלקטרוניקה מבן גוריון. בעל 10 שנות ניסיון באלגוריתמיקה כמפתח, ראש צוות, מנהל פיתוח, פרילאנסר ומנטור למתחילים בתחום. הייתי חלק מפרויקטים רבים, בחלקם עשיתי טוב יותר ובחלקם פחות. ברגעי חשבון נפש כשאני מסכם ושואל איפה יכולתי להשתפר, התשובות המהדהדות במוחי מובילות לדבר אחד:להתעדכן להתעדכן ולהתעדכן!בהרבה מקרים עוד חיפוש, מחקר או סקירת ספרות הייתה גורמת לי להביא תוצאות יותר טובות.וזו הסיבה בגללה החלטתי לכתוב את הבלוג הזה: אם אתחייב לשבת ולכתוב, בהכרח אקרא, ארחיב אופקים, ואתעדכן במה שחדש בתחומי המקצועי.אם על הדרך עוד אנשים יפיקו ערך וילמדו, זה בכלל יהיה נפלא!עם הזמן נוכחתי לדעת שלכתוב ולסכם זה כף, וקיבלתי לא מעט פידבקים חיוביים ולכן אני ממשיך ואף מזמין אחרים לכתוב גם !
בעל תארים ראשונים בהנדסת אלקטרוניקה ובמתמטיקה, ובעל תואר שני בהנדסת אלקטרוניקה מבן גוריון. בעל 10 שנות ניסיון באלגוריתמיקה כמפתח, ראש צוות, מנהל פיתוח, פרילאנסר ומנטור למתחילים בתחום. הייתי חלק מפרויקטים רבים, בחלקם עשיתי טוב יותר ובחלקם פחות. ברגעי חשבון נפש כשאני מסכם ושואל איפה יכולתי להשתפר, התשובות המהדהדות במוחי מובילות לדבר אחד:להתעדכן להתעדכן ולהתעדכן!בהרבה מקרים עוד חיפוש, מחקר או סקירת ספרות הייתה גורמת לי להביא תוצאות יותר טובות.וזו הסיבה בגללה החלטתי לכתוב את הבלוג הזה: אם אתחייב לשבת ולכתוב, בהכרח אקרא, ארחיב אופקים, ואתעדכן במה שחדש בתחומי המקצועי.אם על הדרך עוד אנשים יפיקו ערך וילמדו, זה בכלל יהיה נפלא!עם הזמן נוכחתי לדעת שלכתוב ולסכם זה כף, וקיבלתי לא מעט פידבקים חיוביים ולכן אני ממשיך ואף מזמין אחרים לכתוב גם !
מושג חשוב נוסף על מנת שבהמשך נבין back propagation כמו שצריך הינו הרכבת פונקציות ובהקשר זה את כלל השרשרת.
הרכבת פונקציות הכוונה לשים בשרשרת שתי פונקציות כאשר הפלט של הראשונה יהווה הקלט של השניה ובכך להרכיב פונקציה אחת. למעשה רשת נוירונים היא הרכבה של הרבה פונקציות (שכל אחת נקראת שכבה ברשת). למשל נרכיב את הפונקציה f(x)=x^2-6x+2 עם הפונקציה g(x)=-2x
בסדר הזה f של g וזה לעיתים מסומן ע”י עיגול קטן נקבל לבסוף פונקציה אחת שהינה 4x^2+12x+2
מקבלים זאת ע”י הצבת הפונקציה g(x) שהינו 2x- בכל פעם שמופיע x בפונקציה f(x). ז”א לקחנו את הפלט של הפונקציה g וחיברנו אותה כך שתהיה הקלט של הפונקציה f.
נשים לב שיש חשיבות לסדר ההרכבה, אם היינו מרכיבים שתי פונקציות אלו בסדר הפוך התוצאה הייתה אחרת.
כעת כלל השרשרת chain rule הינו כלל במתמטיקה שאומר איך אפשר לגזור פונקציה שהינה הרכבה של כמה פונקציות שונות. הכלל אומר שכדי לגזור f הרכבה עם g אפשר להכפיל את הנגזרת של f כשמציבים בה בנגזרת את g עם הנגזרת של g. אז בדוגמה שלנו נגזור את g ואת f בנפרד:
נציב בכלל השרשרת וקיבלנו את הנגזרת של ההרכבה:
שימו לב שהיינו ומקבלים את אותה התוצאה אילו היינו גוזרים ישירות את f הרכבה עם g אותה ראינו מקודם:
נתרענן על מושג הנגזרת של הפונקציה. נגזרת של פונקציה חד מימדית בנקודה מסויימת היא השיפוע של המשיק באותה נקודה. ולכן נזגרת מלמדת אותנו אם בנקודה מסויימת הפונקציה בעלייה (שיפוע משיק חיובי) או בירידה (שיפוע משיק שלילי).
המושג גרדיאנט הינו הכללה לנגזרת עבור פונקציות רב מימדיות. ומבחינה גרפית לפונקציות רב מימדיות שנראות כמו יריעה (או משטח עקום כלשהוא) שיפוע של המשיק בנקודה מסויימת כבר לא יחיד אלא תלוי לאיזה כיוון מסתכלים עליו. דמיינו שאתם הולכים על משטח משופע (נניח טיול בשטח שאינו מישורי), דמיינו שאם תפנו מזרחה תהיה ירידה קלה, אם תפנו דרומה תהיה ירידה תלולה, אם תפנו צפונה יהיה מישור ואם תפנו מערבה תהיה עליה קלה. ז”א ההשתנות (עליה או ירידה) תלוי בלאן נפנה.
בעולם חד מימדי ניתן ללכת רק ימינה או שמאלה (על ציר ה x) ולכן נגזרת היא שיפוע המשיק בנקודה כי יש רק משיק אחד לעקומת הפונקציה בכל נקודה. בעולם רב מימדי הגרדיאנט את ההשתנות (עליה או ירידה) בעבור כל כיוון התקדמות אפשרי על עקומת הפונקציה.
גרדיאנט מסומן במתמטיקה כמשולש הפוך וההגדרה המתמטית שלו הינה וקטור המורכב מכל הנגזרות החלקיות של פונקציה רב מימדית.
למשל הגרדיאנט של הפונקציה הדו מימדית f(x,y)=x+4y מורכב מנגזרת הפונקציה לפי x שהיא 1 ולפי y שהיא 4, ז”א [4,1]. ממש לא חייבים להיכנס יותר מזה למתמטיקה בכדי להבין למידה עמוקה כי את אותם הפעולות המתמטיות עושה המחשב ולא אנחנו המפתחים, מה שחשוב זה להבין אינטואיטיבית את המשמעות.
אפשר להתווכח על זה, אבל נניח שמסכימים שמטרת העל של בני האדם הינה להיות מאושרים, ז”א כל פעם שאדם שמח הוא מקבל על כך תגמול פיסיולוגי. ז”א שאנו כבני אדם שואפים להגיע כל הזמן לתגמול הזה. כל אדם פיתח את האסטרטגיות שלו איך להגיע למטרה הזו. למשל יהיו כאלו שיעשו ספורט, יהיו כאלו שיעסקו באומנות וכו’.
גם מי שעוסק בספורט וגם מי שעוסק באומנות ונהנה מכך כנראה יסכים שלא כל רגע בעבודתו מהנה. הרי יש הרבה עבודה קשה וסיזיפית בדרך עד שיוצאת יצירת אומנות שמביאה שמחה ליוצר. ולספורטאי יש הרבה אימונים קשים בדרכו לתהילה. אם כך יש פעולות בלתי מהנות שאנשים מאמינים ש-“משתלמות” כי לבסוף יביאו להנאה.
מה קורה כשיש דילמות ?
אם הספורטאי החרוץ שלנו עכשיו יאכל גלידה זה יסב לו הנאה מיידית אבל זה יפגע בתכנית האימונים שלו לקראת התחרות בשבוע הבא. אם האומן שלנו יקום בבוקר ובמקום להישאר ממוקד בהשלמת היצירה שלו, יקרא עיתון או יצפה בסרט זה יסב לו הנאה מיידית אבל ירחיק ממנו את ההנאה שבלהשלים ולפרסם את היצירה שלו.
לתחום הלמידה החיזוקית Reinforcement Learning יש הרבה במשותף עם בקרה אופטימלית Optimal Control, והוא עוסק במציאת הפעולות שימקסמו פונקציית תגמול בהינתן תגובות מהסביבה.
תודה ל Megajuice
את החישוב המתמטי של מה עדיף בדילמות הללו (פעולה עם תגמול מיידי או פעולה עם תגמול עתידי) בא לפתור אלגוריתם Q-Learning. האות “Q “מסמלת Quality במשמעות של מה הערך שבפעולה מסוימת, ז”א האם תביא לתגמול עתידי יותר או פחות.
האלגוריתם מחזיק מטריצה של ערכים מספריים שמציינים עד כמה משתלם לעבור מכל מצב לכל למצב אחר. למשל אם האומן שלנו קם בבוקר יום של חול ומתלבט אם להמשיך ליצור או ללכת לסרט אזי משתלם לו להמשיך ליצור אבל אם אותה דילמה תוקפת אותו בבוקר יום שבת אזי ייתכן ודווקא יותר משתלם לו ללכת לסרט כדי להתרענן ולקבל השראה כי המוח זקוק ליום מנוחה בשבוע (נניח). ז”א שבפונקצית התגמול יש חשיבות מאיזה מצב (יום חול או יום שבת) לאיזה מצב (ללכת לסרט או להמשיך לעבוד על היצירה) עוברים.
כמו כן ככל שמנסים יותר פעולות מגוונות מעדכנים את האסטרטגיות של איך הכי נכון לפעול כדי לקבל תגמול, המישוואה הבסיסית של האלגוריתם הינה:
מישוואה בסיסית של Q-Learning
ומטרתה לעדכן מהו הערך שבלבצע פעולה כלשהיא על סמך המידע החדש שמגיע בכל רגע נתון.
ערך זה נקבע ע”י הערך הידוע עד כה שבלבצע פעולה ועוד הערך של הפעולה הבאה המשתלמת ביותר.
ובדוגמה שלנו, האומן שקם ביום חול ומתלבט אם ללכת לסרט או להמשיך לעבוד על היצירה שלו ייקח בחשבון את ההנאה שבללכת לסרט אבל גם את ההנאה שבהצגת עבודתו המוגמרת אם לא יילך כעת לסרט ויעבוד על יצירתו. שיקולים אלו בחשיבתו של אותו האומן נולדו עקב ניסוי וטעייה של שנים בהם עבד על פרויקטים והשלים אותם בזמן או שלא השלים אותם בזמן וכך למד את המשמעות והערך שבכך. אותו ניסוי וטעיה הינם מהות המשוואה הנ”ל.
אלגוריתם Q-Learning הוצג לראשונה ב 1989 כעבודת הדוקטורט של Watkins תחת השם: “Learning from Delayed rewards” ז”א ללמוד מתגמולים דחויים.
ב 2014 הראו Google DeepMind שימוש ב Q-Learning עם CNN (ז”א עם למידה עמוקה) ויצרו אלגוריתמים שמשחקים משחקי אטארי ישנים ברמה של בני אדם. לזה קראו Deep Reinforcement Learning למידה חיזוקית עמוקה.
נראה דוגמא נחמדה של אימון רובוט עם ארבע רגליים שלומד איך ללכת קדימה.
בדוגמה זו המשוב ניתן באופן אוטומטי ע”י חיישן אולטרא-סוני שמודד מרחק של הרובוט מנקודת היעד, ז”א כשהמרחק נהיה קצר יותר זה סימן לרובוט שהפעולות שהוא עושה הם נכונות וכך הוא לומד מה כן לעשות כדי ללכת קדימה ומה לא לעשות. נשים לב שאותם ערכי Q ז”א מה עדיף לעשות בכל מצב הינם בהתחלה אקראיים ולכן בתחילת האימון הרובוט מתנענע באופן אקראי. (אולי כמו שהאומן שלנו היה בגיל הילדות או ההתבגרות וניסה כל מיני דברים באופן לא עיקבי)
גם פה אפשר שיש פעולות שלא משתלמות בטווח המיידי אבל כן בטווח הארוך:
הרי כדי שרגליים יגרמו ליצור לצעוד עליהם פעם לעשות צעד ופעם לחזור למצב קידמי שיאפשר את הצעד הבא. החזרה קדימה של רגל כדי שבהמשך תניע את הרובוט קדימה לא תקצר את המרחק ליעד מיידית אבל ניסיון העבר מראה שההחזרה קדימה של הרגל אם יבוא אחריה צעד של הרגל יביא תגמול בהמשך.
מסקנה: אפילו כדי ללכת צריך ללמוד לדחות סיפוקים! נסו להסביר זאת לפעוט בן שנתיים…
מביא כאן טבלה של כמה נביאים מכמה ענקיות שמתעסקות באופן ישיר או עקיף בפיתוח רכבים אוטונומיים. לאחר השמטה של הפרטים, ראו את הנבואות של החזקים בשוק לגבי מתי נראה הרבה רכבים אוטונומיים על הכבישים:
Year
Company
2020
Nvidia
2020
Audi
2020
NuTonomy
2019
Delphi & MobilEye
2021
Ford
2019
Volkswagen
2020
GM
2021
BMW
2020
Toyota
2021
Tesla
2025
US Secretary of Transportation
2030
UBER
2024
Jaguar and Land-Rover
2025
Daimler
2020
Nissan
בכדי לאמן רשת נוירונים לנהוג ברכב יש לאמן אותה עם מגוון סוגי נהיגה, מצבי נהיגה, מזגי אוויר שונים. כמויות המידע איתם מאמנים לנהיגה הינם בסדרי גודל של petabytes (ז”א אלפי טרבייטים terabytes).
השחקניות הגדולות במרוץ לרכב האוטונומי (Ford, GM, Waymo, Tesla) מחזיקות צי של מאות רכבים שמוסיפים למאגר המידע שלהם בקצב שיכול להגיע למיליון מיילים ליום שנועד לאמן ולשפר את האלגוריתם שלהם. כמובן שמאגר נתונים של נסיעות אמיתיות לא מספיק ומשקיעים הרבה גם בלבנות סימולציה של נתוני נהיגה (למשל פלטפורמת הקוד הפתוח לסימולציה של רכבים אוטונומיים Carla).
נתוני נסיעה לא אומר רק תמונות (וידאו) ממצלמות היקפיות אלא גם מחיישנים נוספים שבניהם רדאר ולידר.
תודה ל Texas Instruments
ההיסטוריה המדעית מלאה ניסיונות לאוטומטיזציה של רכבים עוד מהמאה הקודמת, למשל ALVINN הינו פרויקט אמבולנס צבאי אוטונומי מבוסס רשת נוירונים בת שתי שכבות מאוניברסיטת Carnegie Mellon משנת 1989:
https://www.youtube.com/watch?v=ilP4aPDTBPE
במאמר הזה של אנבידיה מספרים על איך אימנו רשת לשלוט בהגה בהינתן הוידאו של מצלמה קידמית והGround Truth של איך נהג סובב את ההגה בכל רגע של הנסיעה. במאמר הם מוכיחים שעל אף שלא הכניסו לאלגוריתם כללים של על מה להסתכל בתמונה ואיך להזיז את ההגה כלל, האלגוריתם למד בעצמו (אחרי האימון) מה חשוב בתמונה כדי להחליט איך לסובב את ההגה. (ניתן לראות בתמונות שמה שמודגש בירוק אלו האזורים בתמונה שהרשת המאומנת מחשיבה כחשובים לקבלת ההחלטה שלה איך להסיט את ההגה)
תודה לאנבידיה
ז”א הרשת מבינה מה חשוב בתמונה (שולי הכביש) ומה לא רלוונטי כרגע לצורך השליטה בהגה.
אגב, את טעויות הנהיגה: ה-“כמעט סטייה מהנתיב”, או ה-“כמעט תאונה” הוסיפו באופן סינטטי ע”י הסטת תמונת הנתיב, כי הרי על האלגוריתם גם ללמוד הרבה מאיך מתקנים הגה כשצריך, ולייצר נתונים כאלו אמיתיים זה טיפה מסוכן…
לאחר שאימנו את האלגוריתם עם רשת CNN=Convolutional Neural Network בת תשע שכבות, בחנו אותו על סימולציה שמציגה לאלגוריתם וידאו של אותה מצלמה קידמית שנבנה בצורה סינתטית על בסיס וידאו אמיתי (ז”א לקחו פריימים אמיתיים שצילמו והסיטו אותם כך שייראה שיש סטייה מהמסלול). בריצת הסימולציה אפשרו לנהג (אנושי) לתקן את ההיגוי כשצריך. כדי לבחון עד כמה האלגוריתם בשל לחיים האמיתיים הגדירו מדד לרמת האוטונומיות שמבוסס על מספר הפעמים שבו הייתה התערבות אנושית לנהיגה, וכשהאלגוריתם נהיה מספיק אוטונומי (מינימום התערבויות בסימולטור) יצאו לנסיעת מבחן אמיתית, ראו את התוצאה:
בעתיד (ובהווה) במקום לשוטט באתרי קניות ולחפש מה שמעניין אותנו, נציג, ספק אנושי יקצר לנו זמנים, יראה לנו מה שמעניין אותנו, ייתן לנו פרטים ולבסוף גם ימכור לנו. ראו איך פייסבוק מסבירים על חווית קניה עם צאטבוט:
צאטבוטים אומנם נתנו קפיצה התפתחותית בעקבות מהפיכת הלמידה העמוקה, אבל זה דווקא אחד הנושאים בהם האלגוריתמים עוד רחוקים מלעבור את מבחן טיורינג (שאומר שלא ניתן להבדיל אם מדובר באדם או מכונה).
אז איך עובד הקסם הזה ?
להגדיר באופן ידני מערך תסריטי שאלות-תגובות לצאטבוט זה כמובן אפשרי ובהחלט קיים ברשת אך זה מאוד מוגבל, הצאטבוטים המוצלחים יותר הינם מבוססי Machine Learning.
לפי הגישה הג’נרטיבית Generative המודל הבסיסי לצ’אטבוט הינו אותו מודל המשמש לתירגום של טקסט ונקרא סדרה לסדרה seq2seq.
ארכיטקטורת seq2seq המשמש לניתוח שפה
ארכיטקטורת seq2seq המשמש לניתוח שפה
מודל זה מורכב ממקודד Encoder, צד שמאל בתרשים שמקבל את המשפט הקודם, וממפענח Decoder, צד ימין בתרשים שמחזיר את משפט התגובה. כל אחד מאותם מרכיבים “מקודד” ו-“מפענח” הינם רשת RNN=RecurrentNeural Network. רשת RNN מקבלת קלט סדרתי (מילה מילה במקרה שלנו) ומעדכנת משתני מצב נסתרים בתוכה תוך כדי הוצאת פלט.
הסבר על התרשים:
התרשים קצת לא ברור למי שלא מכיר RNN ולכן אנסה להסביר אותו ואת ההיגיון שיש מאחורי מבנה זה:
חישבו על משפט בן שלוש מילים שמקבל הצאטבוט ועל משפט שהוא מחזיר בן ארבע מילים. על כל משפט להסתיים בסימון מקובל של סוף משפט.
הסבר על החיצים האנכיים:
כל יחידת חישוב של ה Encoder (המלבנים משמאל) מקבלת כקלט מילה מהמשפט שנאמר לצאטבוט וכל יחידת חישוב של ה Decoder (המלבנים מימין) מקבלת את הפלט של היחידה שמשמאלה.
הסבר על החיצים האופקיים:
בנוסף לכך כל יחידת חישוב הן ב Encoder והן ב Decoder מקבלת כקלט נוסף תוצאת חישוב אחרת מיחידת הקלט שמשמאלה שלה קוראים משתני מצב נסתרים. למה הם נסתרים ? כי הם אינם חשופים למשתמש, במילים אחרות הם לא משפט התגובה שייאמר אלא הם משתנים שמכילים מידע שמהותו הקשר המשפט או המבנה התחבירי של המשפט עד כה.
מבנה זה של רשתות RNN שונה ממבנה של הרשתות הקלאסיות שנקראות Feedforward Neural Network בהן כל יחידה רק מקבלת קלט אחד שהינו התוצאה של היחידה הקודמת.
מה ההיגיון שבשימוש ברשתות RNN לניתוח שפה:
כשאנחנו בתור בני אדם שומעים משפט ואנו מחברים בראש משפט כתגובה שמורכב מכמה מילים.
למילים שנבחר למשפט התשובה יש חשיבות לסדר, ז”א כל מילה תלויה הרבה במילה הקודמת לה, אבל כולן גם תלויות בהקשר המשפט כולו.
למשל נשאל צאטבוט: “מהו אירוע הספורט הגדול שיש במלבורן בחודש הקרוב ?”
והצאטבוט יענה: “אירוע הספורט הגדול במלבורן בחודש הקרוב הינו Australian Open Tennis”
משפט השאלה מקודד למשתני מצב נסתרים שמייצרים את משפט התגובה. משפט התגובה יתחיל במילה “ארוע” ואז המילה הבאה כנראה תתאר את המילה הראשונה (למשל יתאים פה אירוע מוסיקלי, אירוע תרבות,…) אבל גם קשורה למשפט השאלה כולו שעסק בספורט, ז”א המילה השנייה הכי סבירה תהיה “הספורט”. זו הסיבה שמבנה שכזה של רשת ש-“זוכר” משתני מצב שמתארים את הקלט ההיסטורי (ולא רק את הקלט האחרון) יעיל בניתוח שפה טבעית (NLP).
ז”א אין באמת אדם כזה במציאות אלא זו תמונה שנוצרה ע”י אלגוריתם שלמד טוב מאוד איך נראים תמונות של סלבריטאים ויצר (ג’ינרט) יש מאין תמונה חדשה שכזו!
רוצים להכיר עוד סלבריטאים שכאלו ?
הטירוף שנקרא GAN החל ב 2014 במאמר של Ian Goodfellow שהראה דרך מקורית וייחודית למודלים גנרטיביים Generative Models. מודלים גנרטיביים הינם אלגוריתמים שיוצרים data יש מאין, בין אם תמונות, וידאו, צלילים, קטעי מוסיקה או דיבור, טקסט או כל סוג אחר של מידע.
אותו מאמר ראשון פתח ממש ענף שלם, חוקרים רבים כל כך התלהבו ופיתחו נגזרות שונות ומגוונות לאלגוריתם הראשוני. מעניין להסתכל על כמות המאמרים בתחום שיצאו מאז:
תודה ל Gan Zoo
אז GAN השתכלל והלך לכיוונים רבים אבל הרעיון היסודי שמתואר במאמר המקורי הינו רעיון מעניין שנלקח מתורת המשחקים. מדובר בשתי רשתות נוירונים: אחת Generator שתפקידה לחולל (לג’נרט) תמונות. והשנייה Discriminator שתפקידה להחליט אם תמונה נראית אמיתית או לא, קצת כמו צורף שמומחה בלזהות זיופים.
כידוע רשת נוירונים צריך לאמן, ולפני האימון היא נותנת פלטים אקראיים ולא מעניינים.
ז”א במקרה שלנו רשת ה Generator הבלתי מאומנת תוציא בהתחלה תמונות של רעש לבן (ז”א תוציא תמונות שבוודאי לא אמיתיות) והרשת Discriminator שניתן לה תמונות לבחינה תחזיר בהתחלה תשובה מקרית (תמונה אוטנטית\תמונה לא אוטנטית ללא קשר למהי באמת התמונה הנבחנת).
ואז נותנים לרשתות לשחק בינהם משחק כזה כך שכל אחת תאתגר את השניה וכך כל אחת מהן תתאמן ותשתפר במשימתה עד שלבסוף הרשת Discriminator כבר תדע בקלות להגיד על תמונה אם היא נראית אמיתית או לא (למשל אם אכן כך נראית תמונה של סלבריטאי) והרשת Generator תדע בקלות ליצור תמונת סלבריטאי שנראית אמיתית.
רשת ה Discriminator מקבלת הן תמונות אמיתיות והן תמונות שיצרה רשת ה Generator.
מה שיוצר את האימון של כל רשת הוא הפידבק מתוצאת הרשת השנייה. הרי הצלחה עבור רשת ה Generator תהיה אם רשת ה Discriminator תגיד על הפלט שלה שהוא נראה אוטנטי. והצלחה עבור רשת ה Discriminator תהיה אם מצד אחד תגיד אוטנטי על תמונות אמיתיות ממאגר תמונות ומצד שני תגיד לא אוטנטי על תמונות שיצאו מרשת ה Generator.
בדיוק כפי שכל תחרות משפרת את שני הצדדים גם אם הם בעלי אינטרסים מנוגדים: למשל בסייבר, ההאקרים משתפרים ככל שאמצעי ההגנה והבטיחות משתפרים ולהיפך, או המלחמה הקרה שהייתה בין ברית המועצות לבין ארצות הברית ששיפרה כל צד בפיתוחי הגרעין שלו.
פונקציות במתמטיקה כולנו מכירים מלימודי בית הספר, הם למעשה אוביקטים מתמטיים שמקבלים מספר אחד או יותר ומחזירים מספר אחד. ניתן לכתוב פונקציה בצורה אלגברית, נניח y=10-x ומוסכם שהקלט הינו x והפלט הינו y.
הדרך להציג אותם בצורה גרפית היא על מערכת צירים בה הקלט והפלט מוצגים על הצירים. אם מדובר בפונקציה חד מימדית, קרי מקבלת מספר אחד ומחזירה מספר אחד היא תהיה מוצגת כך שציר ה X הוא הקלט וציר ה Y הוא הפלט ואז כל נקודה על הגרף מתארת צמד קלט-פלט של הפונקציה. העקומה כולה מתארת את על הקלטים\פלטים האפשריים.
אם מדובר בפונקציה דו מימדית אזי צירי ה x,y מתארים את הקלט וציר ה z הינו הפלט. ואז כשנצייר את כל הקלטים-פלטים האפשריים נקבל יריעה או צורה שטוחה תלת מימדית על מערכת הצירים.
נדבר בהמשך על מושגי הנגזרת והגרדיאנט של פונקציות.
אך ראשית מדוע רלוונטי לדבר על זה בכדי ללמוד deep learning ?
הסיבה לכך נעוצה בהבנת תהליך האימון של רשת נוירונים להצליח במשימה כלשהיא (כמו סיווג). הרשת מקבלת כקלט מידע, מעבדת אותו ע”י כל מיני פעולות מתמטיות שתלויות במשקלים (שם אחר למשתנים או פרמטרים) שלה ומחזירה פלט שנקרא לעיתים פרדיקציה. בתחילה הרשת לא מאומנת, ז”א המישקלים שלה הינם מספרים אקראיים חסרי משמעות ולכן הפרדיקציה שתיתן על קלט כלשהוא תהיה חסרת משמעות ובדרך כלל שגויה. ככל שמאמנים את הרשת יותר כך הפרדיקציה שלה תהיה יותר מהימנה.
תהליך האימון של רשת נוירונים נקרא back propogation. ומשמעותו שינוי המשקלים של הרשת כך שהרשת תצליח במשימה על data ו ground truth נתונים. (מהם אותם משקלים ומה הם עושים נבין בקורס עצמו של למידה עמוקה, כרגע רק נבין שאלו מספרים שקובעים את תגובתה של הרשת לקלט נתון, ולכן מטרתנו בשלב האימון לעדכן אותם להיות אופטימליים)
האימון הוא תהליך מתמשך המורכב מאיטרציות (epochs) כאשר לאורכו הרשת\האלגוריתם אמור להשתפר בביצוע המשימה שלו.
בכל איטרציית אימון הרשת מקבלת פיסות קלט מה training database והפרמטרים או משקלים של המודל\של הרשת מתעדכנים במטרה להשתפר במלאכת הסיווג (או המשימה שבאופן כללי נקרא לה הפרדיקציה).
כדי להחליט איך לעדכן את אותם הפרמטרים\משקולים ישנו את פונקציית ה loss שמחזירה הינו ערך מספרי חיובי (שנקרא loss) שהינו ציון לעד כמה הרשת מוצלחת ברגע מסויים במשימה שלה. כדי לחשב את ה loss יש להתחשב כמובן ב ground truth. כי הרי ה loss מתאר עד כמה הפרדיקציה של הרשת תואמת ל ground truth שניתן לה.
לא נכנס מעבר לזה לפרטים בשלב זה, רק נזכור שכשמאמנים רשת נוירונים ישנה פונקציה שנקראתloss function שמתארת עד כמה הרשת מוצלחת. ובכל איטרציה של אימון כיוון שהרשת משתנה כך גם הערך של ה
Loss function משתנה.
ערך גבוה משמעותו ציון רע – ז”א שהרשת לא טובה במשימתה, וערך נמוך (קרוס לאפס ככל הניתן) משמעותו שהרשת מוצלחת במשימתה.
פונקציית ה Loss הינה פונקציה רב מימדית, ז”א מקבלת כקלט המון מספרים (כמספר המישקלים של הרשת, זה יכול להיות מיליוני מספרים) ומחזירה מספר אחד (שהינו תמיד חיובי).
בקורס למידה עמוקה נראה בדיוק מהי פונקצית ה loss ואיך מוצאים לה את המינימום. בשלב זה רק נבין שמציאת המינימום שלה שקול למציאת הרשת האופטימלית. ז”א אוסף המישקלים של הרשת שמביאים לערכי loss נמוכים ביותר הם אוסף המישקלים שיוצרים רשת שמצליחה במשימה (למשל רשת שמזהה מה רואים בתמונה, או רשת שמזהה מאיזה חומר בדיקה כימית כלשהיא עשוי, או כל רשת שנועדה לפתור בעיית machine learning כלשהיא)
וזאת הסיבה שנדבר על פונקציות ועל מציאת מינימום של פונקציות ועל נגזרות וגראדיאנטים של פונקציות.
Google Brain הינה מחלקת המחקר של גוגל שעוסקת בלמידה עמוקה. המחלקה הוקמה ב 2011 ודוגלת במחקר חופשי. ז”א כל חוקר בקבוצה ראשי לבחור את תחום המחקר שלו תחת החזון של לשפר את חיי האנשים ולהפוך מכונות לחכמות יותר.
בכתבה זו אסקור כמה מנושאי המחקר היותר מעניינים עליהם עבדו ב Google Brain בשנת 2017 על פי הבלוג שלהם.
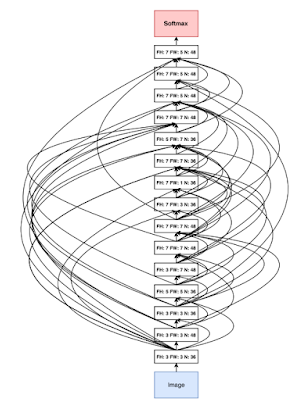
אוטומציה של למידת מכונה AutoMl – המטרה במחקר זה הוא לבנות אוטומציה לבניית פתרונות Machine Learning מבלי התערבות של חוקרים אנושיים. ז”א מדובר באלגוריתמים שבונים אלגוריתמים (בתרשים למטה ניתן לראות ארכיטקטורת רשת שנבנתה ע”י אלגוריתם) , ומסתבר שהאלגוריתמים שנבנים ע”י אלגוריתמים מצליחים לא פחות טוב מאלגוריתמים שמפתחים בני אדם. החזון של המחקר הזה הינו יצירת בינה מלאכותית אמיתית וכללית.
https://ai.google/research/pubs/pub45826
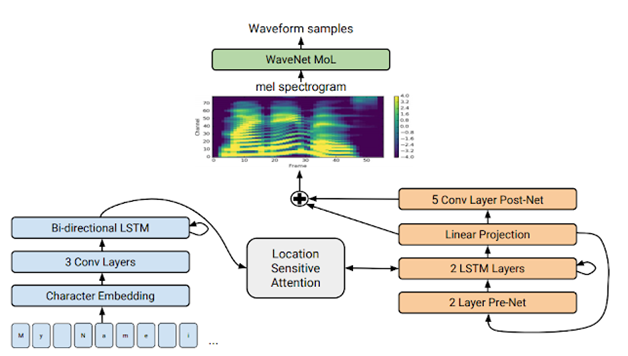
Speech Understanding and Generation – שיפור היכולות של זיהוי ושל יצירה של קול אנושי. בפרט בעיית המרת טקסט לדיבור Text to Speech בה חלה פריצת דרך כשמערכת Tacotron (תרשים המציג את הארכיטקטורה למטה) מדברת מתוך טקסט כלשהוא באופן כזה שעובר את מבחן טיורינג, ז”א שלא ניתן להבדיל אם בן אנוש או מחשב מקריא את הטקסט. האזינו להדגמה כאן!
https://arxiv.org/abs/1712.05884
בתחום Privacy and Security –
במאמר מעניין שעוסק בפרטיות המידע החוקרים מציעים גישה בעזרתה פרויקטים המבוססים על מאגרי נתונים רגישים ופרטיים (למשל תמונות או נתונים של בדיקות רפואיות על אנשים) יוכלו לבנות מודלים מבלי שתהיה להם גישה לנתונים הרגישים. ע”פ הגישה יאומנו מודלים שנקראים “מורים” שהם כן אומנו עם database רגיש. ומודלי המורים יהיו נגישים לשימוש כקופסה שחורה (ללא גישה לפרמטרים שלהם). וכך יוכלו מהנדסים להיעזר באותם “מורים” כדי לאמן מודלים משלהם שנקראים “תלמידים” לבעיות ספציפיות אך ללא גישה למאגרי הנתונים הרגישים. האימון של התלמידים ייעשה ע”י ניסיון להתחקות אחרי תשובות המורים.
https://arxiv.org/pdf/1610.05755.pdf
Understanding Machine Learning Systems –
הרבה מחקר נעשה כדי להבין איך רשתות למידה עמוקה עובדות, איך לפרש אותן ואיך להנגיש אותן בצורה ברורה לקהילה. בהקשר זה התאגדו Google, OpenAI, DeepMind, YC Research והשיקו מגזין אונליין בשם Distill שנועד לעזור לאנשים להבין למידת מכונה. האתר גם מספק כלים ויזואליים להמחשה של אלגוריתמים – שווה להכיר!
בעיות AI כמו תירגום, זיהוי פנים או תמונה או קול, ועוד נפתרות היום יותר ויותר בהצלחה עם למידה עמוקה.
בדרך כלל ניתן לומר שפתרון עם למידה עמוקה משמעותו רשת נוירונים עמוקה שהינה בעצם אוסף פעולות מתמטיות בסדר מסוים, ונוהגים לסרטט אותה למשל כך:
רשת נוירונים לדוגמא
כל עיגול מייצג איזושהיא פעולה מתמטית וכל קו שמחבר בין עיגולים משמעותו שתוצאה עוברת לפעולה הבאה. יש אינספור דרכים לבנות את הארכיטקטורה של הרשת. (מהם הפעולות המתמטיות, מה הסדר שלהם, מי מחובר למי וכו’)
בכל הדוגמאות שרואים, בונים אלגוריתם\רשת נוירונים שמיועדת לפתור בעיה ספציפית. רשת שמצליחה טוב במשימה אחת לא בהכרח תתאים למשימה אחרת.
כדי לבנות ארכיטקטורת רשת שתפתור בעיה כלשהיא נדרשת עבודת ניסוי וטעייה של צוותי חוקרים ומהנדסים מומחים בתחום. אבל האם כדי לבנות ארכיטקטורה מנצחת דרושה מומחיות או אומנות ברמה גבוהה כזו ? או אולי זו תוצאה של ניסוי וטעייה אקראי שגם קוף יצליח לפעמים ?
אז גוגל לא משתמשת בקופים כדי לעצב את הארכיטקטורות רשת של המחר, אבל הם כן משתמשים בלמידה עמוקה כדי לעצב למידה עמוקה, מה שנקרא AutoML = Auto Machine Learning.
שתי גישות קיימות למחקר זה: אלגוריתמים גנטיים או אבולציוניים (evolutionary algorithms) ו- למידה חיזוקית (reinforcement learning). בשתי גישות אלו החוקרים מנסים למצוא דרך אוטומטית שתעצב ארכיטקטורת רשת שתפתור את בעיית סיווג התמונה בין השאר במאגר התמונות CIFAR. CIFAR הינו מאגר של 60,000 תמונות צבעוניות קטנות בגודל 32X32 פיקסלים עם 10 מחלקות שונות (CIFAR10) או עם 100 מחלקות שונות (CIFAR100), מאגר זה נועד לצרכי מחקר ופיתוח אלגוריתמי סיווג (classification) של תמונות.
האלגוריתם הגנטי בוחן ביצועים של כל מיני ארכיטקטורות רשת על database כלשהוא ואת הלא טובים הוא מוחק ואת המוצלחים הוא הופך להורים ש-“מולידים” ארכיטקטורות רשת חדשות שנבדלים מההורים שלהם ע”י מוטציה קטנה ואקראית. ז”א משנים פרט כלשהוא בארכיטקטורות הרשת הצעירות (שינוי פונקציית האקטיבציה, שינוי היפר-פרמטרים, גדלי פילטרים וכו’) ואז חוזרים על תהליך הברירה הטבעית הזו עד שמגיעים לארכיטקטורת רשת מוצלחת במיוחד. בתרשים ניתן לראות גרף של אחוז הדיוק של הרשת (בבעיית קלאסיפיקציה של תמונות) עם הרבה נקודות אפורות המייצגות ארכיטקטורות רשת ש-“מתו” ע”י תהליך הברירה הטבעית ומעט נקודות כחולות ששרדו והן בעלי אחוזי הדיוק הטובים ביותר. ניתן גם לראות דוגמאות לחלק מהנקודות: ז”א ארכיטקטורות שיצאו מהתהליך, הימנית היא הטובה ביותר ומשמאל אבותיה הקדמונים.
רשתות נוירונים שפותחו ע”י אלגוריתמם גנטי תודה ל https://arxiv.org/pdf/1703.01041.pdf
בלמידה חיזוקית Reinforcement learning לעומת זאת, משתמשים בייצוג של ארכיטקטורת רשת כמחרוזת תווים באורך לא קבוע (מחרוזת שמכילה את כל המידע של הרשת: גדלי הפילטרים, ה strides, וכו’) ובאמצעות Recurrent neural network מייצרים מחרוזת טובה יותר ויותר על בסיס תגמול שנובע מביצועי הרשת על מאגר תמונות כלשהוא. האימון נעשה בשיטת Policy gradients ולבסוף מתקבלות ארכיטקטורות רשת שפותרות את הבעיות שרשתות שעוצבו ע”י בני אדם פותרות אותן ברמה לא פחות טובה (מבחינת דיוק ומהירות). ניתן למשל לראות בתרשים ארכיטקטורת רשת שאומנו על מאגר הטקסט Penn Treebank (מאגר המשמש לניתוח שפה) כאשר הרשת השמאלית פותחה ע”י חוקרים אנושיים והימנית פותחה ע”י למידה חיזוקית.
רשתות נוירונים שפותחו ע”י בני אנוש או על ידי אלגוריתם תודה ל https://arxiv.org/pdf/1611.01578.pdf
יש מן המשותף בין הארכיטקטורה שפותחה ע”י בני אנוש לבין זו הפותחה כתוצאה של אלגוריתם כמו הסכימות (האלמנטים הכתומים) בשורה התחתונה, אך גם יש אלמנטים שהחוקרים לא ראו תועלת בעצמם כמו המכפלה (האלמנט הכחול בשורה התחתונה משמאל). אם כי מעניין שה-“שיטה המוזרה” שיצאה באופן אוטומטי כן הוצעה באופן פשטני יותר ע”י קבוצת חוקרים אחרת בזמן אחר.
מעורר מחשבות על מהות הניסוי והטעייה האנושי של מציאת אלגוריתמיקה אופטימלית ועד כמה הוא “טכני”, הלא כן ?
מתי נראה הרבה רובוטים שעובדים במפעלים, משרתים אותנו בבתי קפה, מנקים לנו את הבית ואת הרחוב או מחליפים הרבה בעלי מקצוע אחרים ?נראה שלא ממש בקרוב! אחד הקשיים הוא כמות הזמן שיש לאמן את הרובוטים על כל משימה.התחום המבטיח בהקשר זה הינו Reinforcment learning או בעברית למידה חיזוקית. תחום זה הינו ענף ב machine learning – למידת מכונה שקיבל השראה מפסיכולוגיה התנהגותית. בעולם זה יש סוכן (רובוט\מכונית\תוכנה) שפועל בסביבה כלשהיא ומקבל מידע או חש את סביבתו. למשל אם מדובר במכונית אוטונומית אזי היא מקבלת תמונות היקפיות, חיישני תאוצה ולעיתים תמונת מכ”ם והיא יכולה לפעול בסביבה (בכביש) שזה אומר ללחוץ על הגז או הברקס או לסובב את ההגה:
אם למשל מדובר באלגוריתם שמטרתו לשחק במשחק האטארי המפורסם Breakout (פריצה) אזי האלגוריתם מקבל את תמונת המסך והפעולות שיכול לעשות הינן להזיז ימינה או שמאלה את השולחן:
בגישת ה reinforcement learning על כל פעולה שמבצע הסוכן הוא מקבל תגמול (שהינו ערך מספרי) שמייצג עד כמה הפעולה הייתה חיונית או לא חיונית להשגת המטרה ובהתאם לכך הסוכן מעדכן את המדיניות שלו עבור הפעולות הבאות. קצת כמו לאלף כלב…מהפיכת הלמידה העמוקה הראתה לעולם שאימון עמוק (ז”א מודלים גדולים במיוחד) עם database גדול במיוחד מצליח באופן מפתיע איפה שגישות קלאסיות נכשלות. על אף שתחום ה reinforcement learning ותיק, בגילגוליו הראשונים החל בשנות החמישים אך כמו הרבה תחומים, החיבור שלו עם הלמידה העמוקה (deep reinforcement learning) נראה מבטיח מאוד לחוקרים רבים.כמה זמן צריך להתאמןעל דוגמאות צעצוע ?לפי המאמר של openAi משך הזמן שדרוש לאמן אלגוריתם Rainbow DQN עד שמשחק במשחקי אטארי טוב לפחות כמו בן אדם הינו 83 שעות משחק.דוגמה אחרת הינה לאמן למשימות בסימולציה MuJoCo שם כמות האימונים נעה בין מאות אלפים לעשרות מיליוני צעדים.MuJoCo הינו מנוע המדמה את חוקי הפיסיקה שנועד לעזור למחקר בתחום הרובוטיקה. זה בעצם חוסך ניסויים ברובוטים פיסיים באמצעות סימולציה וירטואלית. למשל משימות כגון לגרום לרובוט ללכת, לעלות במדרגות, לתמרן בין מכשולים וכו…
לפי המאמר של Deepmind נדרשו מעל 100 שעות אימון מקבילי כדי להגיע לביצועים שניתן לראות בסרטון.אלו דוגמאות יחסית פשוטות,כמה זמן צריך להתאמןעל דוגמאות מהעולם הפיסי ?נראה שהתשובה לא ברורה לגמרי אבל מדובר בהרבה מאוד, אולי הרבה יותר נתונים ממה שסביר לאסוף.אם נסתכל על פעולות פיסיות פשוטות כמו פתיחת דלת, הרמת חפץ או הזזה של חפץ:
נראה שלמשל להרמת חפצים על הרובוט לבצע לפחות 800,000 חזרות (של ניסוי וטעייה) וזה יביא אותו רק לבשלות חלקית כי אם הסביבה קצת משתנה הוא פחות יצליח.ולגבי משימות קצת יותר מורכבות עם תנאי סביבה משתנים, כמו למשל נהיגה אוטונומית, עוד ב 2015 דיבר אלון מאסק מנכ”ל טסלה על בערך מיליון מיילים של נהיגה מבוקרת (נהג אוטומטי בפיקוח נהג אנושי) ליום שמתווספים לאינטליגנציה המשותפת של האלגוריתם נהיגה אוטונומי. ב 2016 כבר דיברו צבירה של 780 מיליון מיילים של נהיגה וקצב אגירת המידע גדל למיליון מיילים כל עשר שעות.אז תקציבים לאימון אלגוריתמים של נהיגה אוטונומית לא חסרים בעולם וזה אכן מתקרב, אך פעולות אחרות אנחנו עוד לא רואים הרבה.לסיכום הרובוטים עדיין מתנהגים כמו כלבים קשים לאילוף, או שאנחנו עוד לא למדנו את אומנות האילוף היעיל!
תיקון טעות בהקלטת הפרק, אמרתי ש precision-recall מבלבל… 🙂
Precision של מחלקת התפוחים – הינו מספר הפעמים שסיווג האלגוריתם תמונות תפוחים כתפוח לחלק למספר הפעמים שסיווג האלגוריתם תמונות תפוחים כתפוח ועוד מספר הפעמים שסיווג האלגוריתם תמונות תפוחים כבננות. מדוע מדד זה לא מספיק, כי הרי גם אלגוריתם טיפש שתמיד מחליט שזה תפוח יקבל ציון 100% ב precision. (כל 60 תמונות התפוחים יגיד שזה תפוח, אבל זה לא אלגוריתם מוצלח בכלל כי גם על 40 בננות אומר שזה תפוח)
לכן המושג המשלים שלו הינו Recall.
Recall של מחלקת התפוחים – הינו מספר הפעמים שסיווג האלגוריתם תמונות תפוחים כתפוחים לחלק ללמספר הפעמים שסיווג האלגוריתם תמונות תפוחים כתפוחים ועוד מספר הפעמים שסיווג האלגוריתם תמונות בננות כתפוחים. (שימו לב שגם precision וגם recall הם אותו המונה לחלק למכנה אחר)
אותו אלגוריתם טיפש שתמיד מסווג תפוח יקבל ציון recall 60%.