
תהליכי קבלת החלטות רבים מסתמכים היום על אלגוריתמים מבוססי בינה מלאכותית, למשל סיווג של מועמדים למשרות, הערכת הסיכוי של עבריין מורשע לחזור לפשוע, אישור או דחייה של בקשת הלוואה, וכו’. ככל שתחום הסמכויות של האלגוריתמים גדל, עולה הצורך לוודא שהאלגוריתמים הוגנים ושהם לא מפלים לרעה קבוצות באוכלוסיה על סמך מאפיינים כמו גזע, מין ונטייה מינית. ברשומה הזו נדון בכמה מהבעיות בתחום ואף נדגים שתיים מהן.
בעיות בפונקצית המטרה ובחומר האימון
באימון של מודלי למידת מכונה אנחנו עושים אופטימיזציה למטריקות כמו דיוק שלוקחות בחשבון את המקרה הממוצע. מערכי נתונים נוטים להכיל מעט דוגמאות לאוכלוסיות קטנות, וכך קורה שהמודל לומד פחות טוב את האוכלוסיות הקטנות האלה, ואחוז הטעות עליהן גבוה יותר. לדוגמה, זיהוי פנים נחשב לבעיה פתורה, אבל מחקר שבחן מקרוב את המודלים גילה שהם אמנם עובדים טוב עבור פנים של גברים לבנים, אבל בעשרות אחוזים פחות טוב עבור נשים שחורות. זה תוצר ישיר של אחוז דוגמאות האימון של נשים שחורות במערך הנתונים, והמשמעות המעשית של מודל כזה שהותקן בשדה תעופה היה שנשים שחורות עוכבו בבדיקות ביטחוניות יותר מגברים לבנים.

כדי להמחיש, נסתכל על דוגמת צעצוע של מודל לזיהוי פנים שמאומן על מערך נתונים מאוד מוטה, עם הרבה תמונות של גברים ומעט תמונות של נשים. התוצאה היא שביצועי המודל כמעט מושלמים עבור גברים, אבל הרבה פחות טובים עבור נשים.
בעיה נוספת הקשורה למטריקה היא שהיא לרוב לא נותנת משקל שונה לטעויות שונות. לא בטוח שזה מצב רצוי, כלומר, היינו רוצים שתיוג אוטומטי של תמונה עם אדם שחור כגורילה ייחשב לטעות חמורה הרבה יותר מאשר לטעות בין צ’יוואווה למאפין.
זליגה של הטיות אנושיות (bias) לתוך האלגוריתמים
ניקח לדוגמה את המקרה שהופיע בחדשות לאחרונה, לפיו חברת אמזון השתמשה באלגוריתם בינה מלאכותית כדי לסנן קורות חיים של מועמדים לעבודה, והאלגוריתם התברר כמפלה לרעת נשים. גם מבלי לדעת כלום על המודל שאמזון פיתחו, אפשר לנחש היכן עלולות להתעורר בעיות. אחת הבעיות הנפוצות בסיווג מונחה, שנידונה בפירוט בספר Weapons of Math Destruction של קאת’י אוניל, היא בעיית הפרוקסי: הרבה פעמים אין לנו דרך למדל את מה שאנחנו רוצים למדל באמת, למשל, לחזות את רמת ההצלחה של מועמד לעבודה בתפקיד מסוים. במקום, אנחנו מתפשרים על פרוקסי, למשל, האם עובד כוח אדם שסינן קורות חיים של מועמדים עבור משרה אחרת בעבר החליט להעביר או לפסול קורות חיים מסוימים. כך אנחנו מכניסים הטיות אנושיות לתוך תהליך ההחלטה: אם העובד, בין אם באופן מודע ובין אם לאו, העדיף לסנן קורות חיים של נשים עבור תפקיד טכני כי בתפיסה שלו נשים הן פחות טכניות, כעת המודל שלנו ילמד לחקות את ההתנהגות הזו. כאשר משתמשים במודל בהיקף נרחב, הנזק מתעצם.
בעיה נוספת נובעת מהייצוגים שאנחנו משתמשים בהם עבור הנתונים. דיברנו באחת הרשומות הקודמות על ייצוגי מילים. ייצוגי מילים שנלמדים מטקסטים כוללים, באופן לא מפתיע, גם קורלציות סטטיסטיות פחות רצויות. כך יוצא שהוקטור של מתכנת קרוב יותר לוקטור של גבר מאשר לוקטור של אישה, שקרוב יותר למילה לוקטור של עקר/ת בית (homemaker באנגלית, מילה נייטרלית מבחינה מגדרית). באופן אידיאלי היינו רוצים לתקן את החברה ולא את האלגוריתם, כלומר, לעודד שאנשים יעסקו במקצוע שמושך אותם ללא תלות במגדר שלהם. עד שזה יקרה, צריך לקחת בחשבון את ההטיות האלה, כיוון שהן יכולות לזלוג לתוך אלגוריתמים מקבלי החלטה ולהנציח את הבעיה – כלומר לגרום לכך שהאלגוריתם יעדיף גבר לתפקיד של מתכנת.
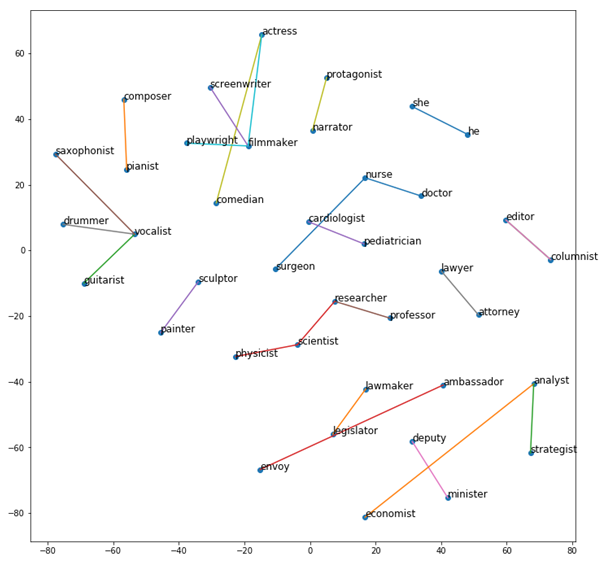
כדי להמחיש, נטען וקטורי מילים מאומנים מראש (GloVe) ונתמקד במילים מתוך רשימת מקצועות. נטיל את הוקטורים למימד 2 ונראה שהכיוון של זוגות מילים כמו doctor/nurse דומה לכיוון של he/she.
מודלי “קופסה שחורה”
ההוגנות של אלגוריתם נפגעת כשלנו המשתמשים של האלגוריתם (או
המושפעים מההחלטות שלו) אין דרך לדעת מה הוביל לקבלת החלטה מסוימת. דוגמה לכך
יכולה להיות אדם המגיש מועמדות לעבודה בחברה גדולה והבקשה שלו נידחת ע”י
סינון אוטומטי של קורות החיים שלו. במקרה הטוב הוא יקבל הודעת דחייה גנרית שלא
מפרטת מדוע בקשתו לא התקבלה, ובמקרה הגרוע הוא פשוט לא יקבל תשובה. בהרבה מהמקרים
האלה הרציונל שמאחורי ההחלטה שקיבל האלגוריתם לא נחשף כיוון שזהו סוד מסחרי של
החברה שפיתחה ומשתמשת באלגוריתם. לאחרונה, עם השימוש בלמידה עמוקה, הדבר נובע
מבעיה אינהרנטית יותר של חוסר היכולת של אלגוריתמים להסביר את ההחלטות שלהם (Explainability).
מכיוון שהפיצ’רים חבויים, גם מפתחי
האלגוריתם לא בהכרח יודעים להסביר מה עומד מאחורי ההחלטה של האלגוריתם.
ניקח לדוגמה מודל שהבנק מפתח על מנת להחליט האם לאשר לאדם כלשהו קבלת הלוואה. בתיאוריה, המודל יכול להיות הוגן יותר מבנקאי המקבל החלטה על סמך תחושת בטן, היכרות אישית עם מבקש ההלוואה, או הטיות בלתי מודעות. במודל כזה אין צורך בפרוקסי: ניתן ללמוד אותו מהלוואות עבר שאושרו, והאם הלווה החזיר את ההלוואה בזמן או לא. עם זאת, עדיין עומדים בפני האלגוריתם אתגרים הקשורים להוגנות: ישנן קורלציות סטטיסטיות שלא נרצה שהאלגוריתם יבסס עליהן את ההחלטה. למשל, בארה”ב אנשים שחורים עניים יותר בממוצע מלבנים. עוני יכול להעיד על יכולת החזרה הלוואה, אבל זה לא יהיה הוגן להשתמש בקורלציה הזו כדי לדחות בקשה להלוואה מאדם רק כי הוא שחור. אנחנו רוצים שהאלגוריתם יקבל החלטה על סמך הנתונים של מבקש ההלוואה, ולא על סמך אנשים דומים לו. לכן, כדי שהאלגוריתם יהיה הוגן ככל האפשר, המפתחים נמנעים מלכלול פיצ’רים רגישים כגון מין וגזע. לכאורה, האלגוריתם עיוור למאפיינים האלה ולכן לא יכול להפלות אנשים לפיהם.
בפועל, לאלגוריתם יש גישה למאפיינים האלה דרך קורלציה למאפיינים אחרים, כמו למשל מיקוד, שיש לו קורלציה גבוהה לגזע בארה”ב. בעוד שבמקרה הזה עדיין יחסית קל לאתר ולהסיר מאפיינים שיש להם קורלציה למאפיינים רגישים, העניינים מסתבכים כשעוברים להשתמש בלמידה עמוקה, והמאפיינים נלמדים גם הם. נניח שהמפתחים מחליטים לייצג את הטקסט הנלווה לבקשת ההלוואה באמצעות וקטור ולהשתמש בו לסיווג. הוקטור יכיל לא רק מאפיינים הקשורים לתוכן הבקשה אלא גם מאפיינים הקשורים בסגנון כתיבה או בחירת מילים, שגם הם יכולים לשמש את האלגוריתם כדי לשחזר את מאפיין הגזע שהמפתחים ניסו להסתיר.
אז מה עושים? אפשר להשתמש בשיטה שנקראת Adversarial Training שבה מנסים באופן אקטיבי להסיר מהייצוג החבוי מאפיינים רגישים. הרעיון הוא לאמן את המסווג הראשי f (האם לאשר הלוואה או לא) על ייצוג X, ובמקביל לאמן מסווג שני g המנסה לחזות את המאפיין הרגיש (מה הגזע של מבקש ההלוואה) מאותו הייצוג X. ע”י גרדיאנט הפוך גורמים ל-f “לשכוח” את מה ש-g למד וכך הייצוג הופך להיות עיוור למאפיין הרגיש. אך לאחרונה יצא מאמר שהראה שגם השיטה הזו לא מסירה באופן מושלם את המאפיינים הרגישים.
ניסיון לפתור את חוסר ההוגנות כרוך הרבה פעמים בטרייד-אוף בין הדיוק של המודל על המקרה הממוצע לבין הוגנות. ירידה בדיוק של מודל של חברה מסחרית עשויה להיתרגם ישירות לאובדן כספי. לכן, מעבר לבעיה הטכנית של כיצד לזהות ולהתגבר על חוסר הוגנות באלגוריתמים, ישנה בעיה גם ברמת התמריץ של החברות המפתחות את האלגוריתמים. עם זאת, החברות הגדולות היום מודעות לנושא ומשקיעות בו משאבים: לגוגל למשל יש צוות שלם המוקדש לנושא.
