
קונספט הAttention צובר תאוצה גדולה בעולם הML בשנים האחרונות ושילובו נהיה פופולרי בתחומים רבים ושונים.
על מנת להבין טוב יותר מהו Attention, בכתבה זאת נענה על השאלות הבאות:
- מהו Attention בעולם הביולוגי, ואיך הוא מיושם בעולם ה AI?
- כיצד מוגדר מנגנון Attention כללי ומהם מרכיביו?
- דוגמא פרקטית לAttention במכונת תרגום
- מנגנון הScaled Dot-Product Attention ב Transformers
בואו נתחיל!
Attention בעולם הביולוגי
Attention, או בעברית – “קשב”, הוא תחום רחב מאוד, שבעולם הביולוגי נחקר לעיתים קרובות בשילוב עם “עוררות”, “עירנות” ו”מעורבות סביבתית”.
בכל רגע נתון, המוח שלנו קולט מספר עצום של סיגנלים מהסביבה (דרך כל החושים במקביל), ועל מנת שנצליח לתפקד, מנגנון ה”קשב” הביולוגי שלנו יודע לתת דגש לסיגנלים הרלוונטיים באותו רגע נתון וביחס למשימה שאנחנו רוצים לבצע.
קשב שמיעתי וקשב חזותי, הם הענפים הנלמדים ביותר מנקודת מבט משותפת של נוירו-מדע ופסיכולוגיה.
לדוגמא, ניקח משימה יומיומית של ניהול שיחת טלפון בסלון. מלבד סיגנלי השמע שמועברים לנו ע”י הטלפון, יש גם סיגנלים ויזואליים וקוליים שמועברים למוחנו מהטלוויזיה, סיגנלי דיבור שהנקלטים מהאנשים שאיתנו בסלון ומדברים ביניהם, סיגנלי קול של רעשים מבחוץ, ועוד…
על מנת שנוכל לנהל את שיחת הטלפון בצורה הטובה ביותר, עלינו להתמקד במידע המתקבל מהטלפון, גם אם העוצמות של שאר הסיגנלים הסביבתיים גבוהות יותר. מי שאחראי לכך, הוא מנגנון הAttention במוחנו, שיודע תוך כדיי עיבוד כלל המידע שנקלט, להדגיש את המידע החשוב לביצוע המשימה בכל רגע נתון, ולהחליש את כל המידע שלא רלוונטי למשימה.
דוגמא יומיומית אחרת היא של קשב חזותי, כאשר מציגים לנו תמונה בהקשר מסוים–נניח של פרי על רקע של חוף ים, ומבקשים מאיתנו לזהות את סוג הפרי. אמנם כל התמונה נקלטת אצלנו במוח, אבל מנגנון הAttention ממקד אותנו במידע הנקלט על האובייקט שרלוונטי לנו (צבע, צורה וכו’), ומעמעם את המידע הלא רלוונטי כמו עצים ברקע, ים, שמיים, אנשים וכו’.

(עכשיו אחריי שהסתכלתם על התמונה וזיהיתם את הפרי, תוכלו בלי להסתכל שוב, להגיד כמה אנשים יש בחוף? 🙂
דרך אגב, תכונת “חלוקת קשב” , משמעותה, שהמוח יודע להדגיש ולעבד סיגנלי מידע שנקלטים במקביל, לטובת ביצוע של מספר משימות אשר שונות אחת מהשנייה.
Attention בעולם ה AI
במודלים של רשתות נוירונים מלאכותיות, יישום מנגנון ה Attention מתבטא בהדגשה דינאמית של המידע הרלוונטי ביותר מתוך כלל המידע הנתון, ושימוש בחלקים הבולטים ממנו.
הדמיון לתהליך הטבעי שקורה במוח האנושי והיכולת ליישם את התהליך בצורה דינאמית עבור כל פיסת דאטה חדשה שנכנסת למערכת, הם שהפכו את קונספט ה Attention לכלכך פופולארי בעולם למידת המכונה.
מאיפה זה התחיל?
מנגנון ה Attention בלמידת מכונה,הוצג לראשונה במאמר של Bahdanau et al.(2014) בו הכותבים מנסים לפתור את בעיית צוואר הבקבוק במודלים של seq2seq מבוססים Encoder-Decoder. במודלים אלו, המידע מכל סדרת הקלט, נאסף לווקטור בעל מימד קבוע במוצא ה Encoder(hidden vector). ככל שהסדרה יותר ארוכה או מורכבת, ככה היכולת של אותו ווקטור “לתפוס” את המידע הרלוונטי מכל הקלט פוחתת. כתוצאה מכך, כאשר הקלט הוא ארוך ומורכב, הביצועים של מודלים אלו פוחתים, מכיוון שמידע רלוונטי “נשכח” ולא מתבטא ב hidden vector שהופך להיות צוואר הבקבוק של המודל.
במאמר, הכותבים הציגו את מנגנון ה Attention עבור מודל Encoder-Decoder, אשר מומש ע”י ארכיטקטורת RNN לכל אחד מהצדדים.
כאן בכתבה, נציג תחילה את האלגוריתם הכללי למימוש מנגנון ה Attention, ולאחר מכן נראה כיצד הוא בא לידי ביטוי במודלי ה Transformers הנפוצים היום בעולם ה NLP וה VISION.
אז איך זה עובד?
לצורך ההמחשה, נניח שסדרת הדאטה שלנו היא טקסט שמורכב מרצף מילים. כל מילה מיוצגת ע”י word embedding (משפחת אלגוריתמים המשמשת לייצוג ווקטורי מילים לטובת ניתוח טקסט). כל מילה מיוצגת ע”י ווקטור בעל מימד קבוע, המקודד את משמעות המילה כך שהמילים הקרובות יותר במרחב הווקטורי צפויות להיות קרובות יותר גם במשמעות שלהן.
במנגנון ה Attention הכללי, משתמשים ב3 מרכיבים עיקריים שמחושבים על בסיס הדאטה הקיים:
- Q – queries
- K – keys
- V – values
לכל איבר i בסדרה (word embedding – במקרה שלנו), יחושבו 3 ייצוגים וקטוריים נלמדים (Qi, Ki, Vi). ייצוג הקלט (נניח של מילים) כווקטור מספרים זו בעיה מורכבת, ולכן נותנים לרשת כמה אפשריות בלתי תלויות ללמוד אותם.
(Q, K, V) מייצגים את הייצוגים של כלל האיברים בדאטה (אפשר להסתכל עליהם כאל מטריצות שמורכבות משרשור הווקטורים).
בדרך כלל, את הפרמטרים הווקטוריים של ה Attention, נחשב בעזרת טרנספורמציה לינארית (מטריצה\רשת FC) משותפת לכל האיברים בדאטה, אשר תאותחל בצורה רנדומאלית, ותתעדכן במהלך האימון:
עבור קלט של T מילים {wt}, מנגנון ה Attention מורכב מהשלבים הבאים:
- עבור כל מילה, מחשבים scores אל מול שאר המילים. ה scores מחושבים ע”י מכפלה סקלרית בין ווקטור q של המילה עם ווקטורי k של שאר המילים (כולל זה ששייך לאותה מילה).
לדוגמא ה score של מילה i אל מול מילה j
2. ה scores ששייכים לכל מילה, מועברים דרך טרנספורמציית Softmax , על מנת לייצר משקל יחסי לכל מילה בדאטה.ככל שהמשקל גבוהה יותר ככה כמות ה”קשב” שלנו צריכה להיות גבוהה יותר למילה הספציפית.
לדוגמא זהו ווקטור המשקלים של מילה i:
3. עבור כל מילה, ה attention מחושב ע”י סכום משוקלל של כל ווקטורי ה value בדאטה vt=1..T יחד עם המשקלים היחסיים שחישבנו בשלב הקודם
לדוגמא:
ווקטור ה attention שמייצג את מילה wi
כאשר vt הוא הווקטור התואם ל kt , שעל בסיסו חישבנו את המשקל αt.
דוגמא פרקטית – מכונת תרגום (Machine Translation)
נניח שיש לנו מודל מתרגם מבוסס Encoder-Decoder – הקלט ל Encoder זה טקסט בצרפתית, ומוצא ה Decoder – הטקסט באנגלית.
כל מילה בטקסט הנקלט מיוצגת ע”י 3 ווקטורים שנשמרים בזיכרון המודל (qi, ki, vi) ,אשר מחושבים ע”י מכפלה של ווקטור המוצא ב Encoder(xi) עם 3 המטריצות המשותפות לדאטה שנלמדות תוך כדיי האימון (Wq, Wk, Wv).
עבור כל מילה חדשה שנכנסת למכונת התרגום, לאחר חישוב הווקטורים המייצגים, מחשבים scoresשל ווקטור ה query אל מול ווקטורי ה keys של המילים שקדמו לה (וכבר נכנסו למערכת), שבהמשך יהפכו למשקלים בעזרת פונקציית ה Softmax.
בשלב האחרון, סכום ווקטורי משוקלל של המשקלים עם ווקטורי ה value התואמים ייתן את ייצוג ה attention שמכיל מידע רלוונטי מכל היסטוריית המיליםשיהיה הקלט ל Decoder (ככל שהמשקל עבור מילה מסוימת גדול יותר, ככה אנחנו נותנים לו יותר “קשב” בייצוג הסופי לפניי פעולת ה decoding)
ווקטור ה attention שחישבנו ייכנס ל decoder ובמוצא תיפלט לנו המילה המתורגמת.
עבור המילה הבאה בתור (xt+1), נבצע את אותו תהליך, כאשר הפעם נשתמש רק בווקטור ה query שלה (qt+1), והמשקלים יחושבו בעזרת צמדי ווקטורי key, value של כל המילים שהמודל ראה עד נקודת הזמן הנוכחית – {vt , kt ; t=1..i+1}
*חשוב לציין – בשונה מהדוגמא הקלאסית, בהרבה מקרים ומודלים, מנגנון ה Attention ממומש באופן Bi-directional, כלומר ה attention של כל איבר ברצף (מילה לדוגמא) מחושב לפי המילים שהיו לפניה ואחריה במשפט. לצורת ה Bi-directional יש יתרון עצום בהבנת קונטקסט הרצף בצורה טובה יותר.
מאפיין או חסרון של ארכיטקטורה זו, הוא שהיא מסוגלת לעבוד עם רצף באורך מוגבל, וצריך את כולו. ז”א שאי אפשר להתחיל עיבוד עד שאין את הרצף עד סופו.
דוגמא למודל Bi-directional נפוץ שעושה שימוש ב Attention–BERT.
מנגנון ה Scaled Dot-Product Attention ב Transformers
ככל הנראה, רובכם נחשפתם לראשונה למנגנון ה Attention בהקשר של מודלי ה Transformers שפרצו את תקרת הזכוכית בעולם ה NLP ולאחרונה נהיו גם שם חם בעולם ה VISION.
ה Transformer, הוצג לראשונה במאמר Attention is all you need (2017),ובבסיסו, הוא מודל seq2seq, מבוסס ארכיטקטורות של encoder-decoder שהחידוש העיקרי בו, זה השימוש הייחודי במנגנון ה Attention, לטובת מיקוד ה”קשב” בין כל איבר בסדרה לשאר האיברים.
זהו המודל הראשון, שהסתמך על מנגנון ה Attention בלבד לחישוב ייצוגים של הקלט בהסתמך על היסטוריית קלטים מבלי לעשות שימוש בRNN או קונבולוציות
בחלק זה של הכתבה, נבין כיצד מנגנון ה Attention ממומש במודל ה Transformer ובנגזרותיו. זהו מקרה פרטי של מנגנון ה Attention הכללי שתיארנו בחלק הקודם של הכתבה.
המרכיבים העיקריים של מנגנון ה Attention ב Transformers הם:
- q, k – ווקטורים בגודל dk, מכילים את ה query,key לכל איבר ברצף.
- v – ווקטור בגודל dv , מכיל את ה value לכל איבר ברצף.
- Q, K, V – מטריצות שמאחדות סט של ווקטוריqueries, keys, values בהתאמה.
- Wq, Wk, Wv – מטריצות הטלהממרחב הדאטה הנקלט (word embedding למשל) אל תתי המרחבים של ה queries, keys, values
- Wo – מטריצת הטלה למוצא ה Multi-Head (נפרט בהמשך)
במאמר, הכותבים מציגים גרסה שונה מעט ממנגנון ה Attention הכללי, וקוראים לה Scaled Dot-Product Attention, ועליה בונים את קונספט ה Multi-head Attention.
כפי שתיארנו במנגנון ה Attention הכללי, גם כאן ווקטורי ה q, k, v (הטלות שונות של האיברים ברצף) הם האינפוטים למנגנון ה Scaled Dot-Product Attention.
כשמו הוא, מנגנון ה Scaled Dot-Product Attention, מחשב תחילה מכפלה סקלרית לכל ווקטור q עם כל ווקטורי הk, לאחר מכן ה scale על התוצאה מתבטא בחילוק של המכפלה ב
לקבלת הscore.
בהמשך, כמו במנגנון הAttention הכללי, הscores עוברים בפונקציית Softmax לקבלת המשקלים שמשמשים למשקול ווקטורי ה values.
מטרת הscaling היא למנוע מערכי תוצאות המכפלה הסקלרית להיות מאוד גדולים, ובכךלחלק מערכי הSoftmax להיות קטנים מאוד מה שגורם לתופעת הVanishing Gradient הבעייתית.
לפיכך, החילוק ב scaling factor שבמקרה שלנו הוא
“מושך” את תוצאות המכפלה הסקלרית למטה, ובכך מונע את התופעה.
ובהמשך המשקלים שיוצאים מה softmax
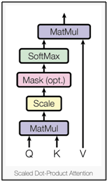
בפועל, החישובים שמבצע מנגנון ה Scaled Dot-Product Attention יכולים להתבצע באופן יעיל בכך שנבצע אותם על סט של ווקטורים בבת אחת.
לכן, נגדיר את Q, K, V להיות המטריצות שמהוות את הקלט למנגנון (נבצע חישוב מקדים של ווקטורי הq, k, v לכל איבר ברצף ע”י מטריצות ה (Wq,Wk,Wv), ולאחר מכן נשרשר אותם לקבלת מטריצות Q, K, V).
ונקבל את נוסחת ה Scaled Dot-Product Attention:
כעת, נציג את תהליך חישוב ה Scaled Dot-Product Attention, שלב אחריי שלב:
- m – כמות האיברים ברצף שנרצה לחשב עבורם את ייצוג הScaled Dot-Product Attention
- n – כמות האיברים ברצף שנרצה להתחשב בהם כקונטקסט שעל בסיסו נחשב לכל ווקטור את ייצוג הScaled Dot-Product Attention
- חישוב ה scores, ע”י מכפלה סקלרית של סט ווקטורי הquery (שורות של מטריצה Q), עם סט ווקטורי ה keys (שורות של מטריצה K).
אם מטריצה Q בגודל nxdk, ומטריצה K בגודל mxdk, תוצאת המכפלה תיהיה בגודל mxn
2. נבצע scaling לכל score ע”י חילוק בפקטור
3. הפעלת Softmax על מנת לקבל סט משקלים עבור כל איבר
4. חישוב סכום משוקלל של סט ווקטורי ה value (שורות של מטריצה V), לקבלת ייצוג ה Scaled Dot-Product Attention
מטריצת V בגודל nxdv, ולכן התוצאה תהיה מטריצה בגודל mxdv כשכל שורה היא ווקטור ייצוג ה Scaled Dot-Product Attention עבור האיבר התואם במטריצת Qdv ובגודל של
Multi Head Attention
על בסיס המנגנון שהראינו, כותבי המאמר הציגו תוספת של Multi Head לתהליך.
ההבדל במימוש הוא שבמקום ליצור סט אחד של ווקטורי queries, keys, values לכל איבר ברצף ע”י סט יחיד ומשותף של מטריצות {Wk,Wq,WV}, מנגנון ה Multi Head Attention
מייצר h סטים כאלה ע”י h סטים משותפים של מטריצות.
לאחר מכן, מנגנון ה Scaled Dot-Product Attention מופעל במקביל על כל אחת מ h ההטלות(ללא תלות אחת בשנייה) ומקבלים במוצא h ווקטורי attention לכל אחד מ m האיברים ברצף.
לאחר מכן, מבצעים שרשור בין כל h הווקטורים ששייכים לכל איבר, לקבלת ווקטור בודד בגודל 1 xhdv . הווקטור המשורשר מוטל ע”י מטריצה Wo לקבלת ווקטור הייצוג הסופי.
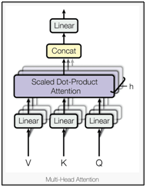
הרעיון שעומד מאחורי ה Multi Head Attention הוא שכעת פונקציית ה attention יכולה לחלץ מידע מהאיברים ברצף שהם מיוצגים במספר תתי מרחב שונים וכך היכולת לחלץ מידע שתומך במשימה ולהדגיש אותו גדלה משמעותית.
פונקצייתה Multi Head Attention יכולה להיות מתוארת בצורה הבאה:
לסיכום
בכתבה זאת, הראינו את המוטיבציה והבסיס למנגנון ה attention בלמידה עמוקה, כמו גם את המימוש של המקרה הפרטי של המנגנון כפי שהוא מיושם במודלים שמבוססים על Transformers.
מי שמתעניין, ורוצה להעמיק עוד יותר, אני ממליץ בחום לקרוא את 2 המאמרים הבאים, שהם בהחלט נחשבים לפורצי דרך בתחום:
- Attention is all you need (2017)
- Neural Machine Translation by Jointly Learning to Align and Translate(2014)
מאמר המציג את השימושים ב attention בעולם ה Computer Vision:
אם לאחר קריאת הכתבה צצות לכם שאלות או שתרצו הרחבה נוספת בנושאים קשורים, מוזמנים לכתוב לי למייל או ליצור קשר ב LinkedIn ואשמח לנסות לעזור 🙂
Barmadar13@gmail.com
