
כשהתחלתי להיכנס לעולם הלמידה העמוקה, טיפסתי באותם השלבים שאני מאמין שרובנו טיפסנו בהם (ואם לא, אני ממליץ בחום על הספר האלקטרוני החינמי של Michael Nielsen בתור התחלה): רשת עם שכבת FC נסתרת אחת, רשת עמוקה, היפר פרמטרים, שכבות קונבולוציה, AlexNet, VGG, Inception וכו’.
גם אני נשבתי בקסם רשתות הנוירונים – היכולת להגיע לביצועים מרהיבים באמצעות מספר שורות קוד (ומספר גדול יותר של שעות אימון וקינפוג, אבל ניחא), היו מדע בדיוני בעיניי. עם זאת, יש דבר שמציק לי לאורך כל הדרך והוא ההבנה בכל פעם מחדש שרשתות לא באמת מבינות מה הן עושות. עכשיו תגידו “בוקר טוב, אלה בסך הכל תוכנות מחשב, למה שיבינו משהו?”. אני יודע אני יודע, אך עם זאת כולנו מכירים את התיאוריה והרעיון שבבסיס רשתות הנוירונים והוא שהן כביכול מחקות את פעולת המוח, ואם זה אכן כך אז איך הן יכולות לעשות לנו כאלה בושות? לעיתים נראה שאין כל קשר בין מה שאנו מצפים מהרשת (ה-ground truth) לבין מה שהרשת ביצעה בפועל. אז נכון, לפעמים אני גם לא מבין את הקשר של מעשים מסוימים של בני אדם לבין המציאות ומבחינה זאת הרשתות האלו דווקא בסדר גמור, אבל לא על זה אני מדבר.
תיאור מילולי של קטגורית התמונות
לצורך הסקופ הזה אני רוצה להתעניין בשאלה איך ניתן לגרום לרשת לסווג קטגוריות שאליהן היא לא נחשפה מעולם או נחשפה רק פעם אחת (zero\one shot detection למתעניינים) על ידי תיאור מילולי בלבד של הקטגוריות? או איך ניתן לגרום לרשת לכך שגם כאשר היא תטעה בסיווג של תמונה, התוצאה תהיה בעלת קשר סמנטי לאמת?
מענה הגון לשאלות אלה יקרב אותנו קצת יותר לחיקוי של דרך החשיבה האנושית.
בארכיטקטורות המוכרות, אלה הכוללות שכבות קונבולוציה, pooling layers ולבסוף שכבת softmax קשה לגרום לרשת להצליח במשימות האלו. בכל תהליך האימון הרשתות מקבלות פידבק של כמה הן רחוקות מהאמת האחת והיחידה (ה-one hot encoding), אין כל דרך להבין קשר בין קטגוריות שונות. במילים אחרות, המימד של תגיות התמונות (ה-labels) מורכב מוקטורים אורתוגונליים חסרי כל קשר אחד עם השני ולכן לא ניתן להעריך כמה חמור דומה לסוס למשל. דוגמה נוספת היא מקרה שבו המאגר שעליו התאמנה הרשת לא מכיל תמונות של זברות אך בזמן שימוש ברשת, לאחר גמר האימון, נרצה לנסות לסווג תמונות של זברות. ב-VGG למשל זה לא יהיה אפשרי.
רשתות המבוססות על embedding vectors פותרות בדיוק בעיות כאלו. לצורך העניין נתמקד במאמר המציג רשת בשם DeVise.
רשת זו בנויה משתי רשתות נפרדות. הרשת הראשונה מבצעת את תהליך ה-word2vec ומאומנת על מסד נתונים טקסטואלי גדול ככל האפשר (ויקיפדיה במקרה שלנו), ואילו החלק השני יהיה CNN להוצאת מידע חזותי מהתמונה כאשר שכבת ה-softmax הוסרה ממנו, מעין transfer learning, במקרה שלנו רשת ה-CNN הינה ה-AlexNet (בכל זאת מאמר מ-2013).

מה הקשר בין word2vec לבין AlexNet אתם שואלים?
פה טמון הסוד. בשלב האימון תג (label) התמונה נכנס לתוך רשת ה-word2vec ומקודד לוקטור במימד 500 או 1000 שאותו ניתן למקם כנקודה במרחב רב ממדי, וכעת נקבל שתגים מאותה הקטגוריה ימוקמו סמוכים האחד לשני (בנוסף נקבל גם קשרים דומים בין תגים עם אותו הקשר – למשל וקטור המחבר בין כלב לכלבלב יהיה דומה מאד לזה המחבר בין חתול וחתלתול – אבל זה נושא לפוסט אחר). במקביל, התמונה עצמה נכנסת ל-CNN כאשר במוצא ה-CNN ישנו וקטור באותו המימד של ה-word2vec. את שני המוצאים האלו מכניסים לפונקציית המחיר (זכרו שכעת התג מיוצג על ידי 500, או 1000, מספרים ולא רק על ידי אחד והמון אפסים כמו ב-one hot encoding) המשלבת אבחנה בין כמה קרוב היה הוקטור במוצא ה-CNN לוקטור לוקטור המתאים לתג התמונה ובנוסף אבחנה כמה רחוק היה הוקטור במוצא ה-CNN משאר הוקטורים שנלמדו במודל ה-skip-gram. בשלב ה-test נכנסת תמונה לרשת והתיוג יהיה זה בעל ה-embedding vector (הוקטור מה-word2vec) הקרוב ביותר לזה שיצא מרשת ה-CNN. שיטה זאת מאפשרת לנו לנצל את המידע הסמנטי מהמרחב הטקסטואלי לשימוש במרחב החזותי על ידי כך שאנו מלמדים את רשת ה-CNN לספק וקטורים קרובים מבחינה מרחבית לתמונות בעלות תיוג עם קשר סמנטי. בכך גם כאשר הרשת שלנו תשגה בתיוג התמונה, ישנו סיכוי גבוה לכך שלטעות יהיה קשר סמנטי לאובייקט שבתמונה.
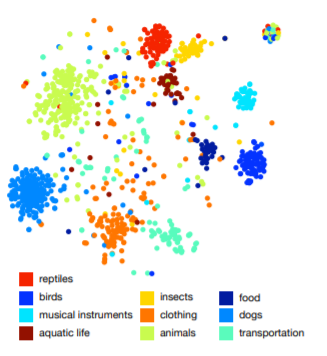
יתרון נוסף בשיטה זו הוא היכולת לסווג אובייקטים שלא נראו מעולם בתהליך האימון. לדוגמא, אם הרשת שלנו לא ראתה מעולם תמונה של חתול וכעת עליה לתייג חתולים בהצלחה, על ידי כל שאנו יודעים שלחתולים יש אוזניים מחודדות ועיניים מלוכסנות נוכל לבדוק האם התמונה שהוכנסה לרשת גרמה לפלט (embedding vector) קרוב מספיק למאפיינים הטקסטואליים באותו המרחב יחסית לשאר התגים.
תוצאות הרשת היו קרובות לאלו שהושגו עם ה-CNN בלבד, אך ככל שבוחנים יותר תיוגים עבור כל תמונת מבחן (משמע, לא בודקים האם הרשת צדקה רק על ידי בדיקת התג שהיה הכי קרוב לוקטור שהופק בזמן המבחן, אלא בודקים את ה-2,3 ואפילו 20 הוקטורים הקרובים ביותר) רשת ה-DeVise השיגה תוצאות קצת יותר טובות מה-CNN המקורית. אומנם לא נראה שיפור בתוצאות אך לפחות לעניות דעתי הכיוון שהוצג במאמר בהחלט מקרב אותנו עוד קצת לכיוון של רשתות ש”מבינות” קצת יותר את העולם הויזואלי שסביבן.
