
סגמנטציה בעולם העיבוד תמונה היא חלוקת התמונה לאזורים. למעשה זו קלאסיפיקציה בה אנחנו מעוניינים לשייך כל פיקסל בתמונה המקורית לאחת ממספר מחלקות (classes) שהגדרנו מראש. התוצאה שמתקבלת הינה תמונה שבה כל פיקסל צבוע בצבע של המחלקה שאליה הוא שוייך.

תודה ל MathWorks https://www.mathworks.com/help/vision/ug/semantic-segmentation-basics.html
שני בסיסי הנתונים (datasets) הנפוצים עבור משימה זו הם VOC2012 ו MSCOCO .
אחת הגישות הראשונות והמוכרות של שימוש בלמידה עמוקה (deep learning – או בקיצור DL) עבור בעיה זו הייתה סיווג קטעי תמונה (patch classification) כאשר כל פיקסל בתמונה המקורית סווג בנפרד למחלקה הרלוונטית על ידי הפיקסלים שנמצאים סביבו באותו קטע תמונה והפיקסל שאותו אנחנו רוצים לסווג נמצא במרכז. הבעיה המרכזית בשיטה זו שהיא מאוד בזבזנית מבחינה חישובית ולא יעילה מכיוון שישנם המון קטעי תמונה שהם כמעט זהים (פיקסלים צמודים בתמונת המקור ימצאו בקטעי תמונות כמעט זהים).
רשתות קונבולוציה מלאות (fully convolutional networks)
בשנת 2014 הופיעה פרדיגמה / ארכיטקטורה חדשה שפותחה על ידי מספר חוקרים באוניברסיטת ברקלי שנקראת “רשתות קונבולוציוניות מלאות” (FCN=fully convolutional networks). פרדיגמה זו שונה מכל מה שהיה לפניה בכך שהיא מחליפה שכבות מחוברות באופן מלא (fully connected layers) בשכבות קונבולוציה וע”י כך מאפשרת לקבל בכניסה לרשת תמונות בגדלים שונים. כמו כן היא גם הרבה יותר מהירה משיטת סיווג קטעי תמונה. מאז, כמעט כל השיטות שהביאו לביצועים הטובים ביותר עבור בעיה זו השתמשו בארכיטקטורה זו.
מלבד שימוש ברשתות מחוברות באופן מלא, אחת הבעיות המרכזיות בשימוש ברשתות עצביות קונבולוציוניות (CNN’s) עבור משימת הסגמנטציה הינה שימוש בשכבות אגרגציה (pooling layers). שכבת האגרגציה מסתכלת על איזור מסוים בתמונה ולוקחת את הערך הגדול ביותר ומעבירה אותו הלאה לשכבה הבאה. הבעיה בפעולה זו היא שאנחנו מאבדים מידע אודות המיקום המקורי המדויק שבו נמצא אותו פיקסל. סגמנטציה דורשת את היישור המדויק של מפות המחלקות, ולכן, צריך גם את המידע אודות המיקום.
אחת השיטות להתמודד עם בעיה זו הינה ארכיטקטורת מקודד-מפענח (encoder-decoder). המקודד מפחית בהדרגה המימד המרחבי (spatial dimension) באמצעות שכבות אגרגציה ואילו המפענח מגדיל בהדרגה את המימד המרחבי. ישנם בדרך כלל קשרי דילוג (skip connections) בין המקודד למפענח עבור שכבות מקבילות, על מנת לעזור למפענח לשחזר את התמונה לגודלה המקורי ולספק מידע אודות המיקום המדויק של כל פיקסל בתמונה המקורית. רשת פופולרית שפועלת על פי ארכיטקטורה זו היא U-Net.
תודה ל U-Net: Convolutional Networks for Biomedical
Image Segmentation
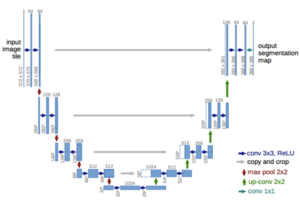
כיצד עובדת רשת U-Net?
הרשת מורכבת משני חלקים – החלק המצמצם (החלק השמאלי בתרשים) והחלק המרחיב (החלק הימני בתרשים). החלק המצמצם בנוי לפי ארכיטקטורה קונבולוציונית טיפוסית, פרוצדורות של 2 קונבולוציות בגודל 3×3 ללא שכבת אפסים מסביב לתמונה (padding) שאחריהן באה פונקציית אקטיבציה מסוג RELU, כאשר לאחר הקונבולוציה השניה מפעילים שכבת max pooling בגודל 2×2 עם קפיצות של 2 פיקסלים בכל פעם (stride=2) שמחזירה את הערך הגבוה ביותר בכל ריבוע בגודל 2×2 בתמונה. המטרה של שכבת הmax pooling הינה להקטין את גודל התמונה. אחרי כל פרוצדורה מספר מפות הפיצ’רים (feature maps) גדל פי 2 וגודל התמונה קטן פי 2.
החלק המרחיב של הרשת גם הוא מורכב מפרוצדורות בדומה לחלק המצמצם אך מטרתו היא הפוכה, להחזיר את התמונה המצומצמת לגודלה המקורי. הפרוצדורות הללו מורכבות מפעולת upsampling על ידי קונבולוציות בגודל 2×2 כלומר שכל פיקסל בתמונה המצומצמת הופך לארבעה פיקסלים בתמונה בפרוצדורה הבאה. בכל פעולת upsampling מספר מפות הפיצ’רים קטן פי 2 ואילו גודל התמונה מוכפל.
בשלב הבא משרשרים בין מפות פיצ’רים מקבילות של המפענח והמקודד (skip connections) כאשר מקטינים את גודלן של כל מפות הפיצ’רים של המקודד (encoder) על מנת שיהיו בעלות גודל זהה לאילו של המפענח (decoder). מטרת פעולת השרשור הינה לשפר את משימת המיקום של הפיקסלים בתמונה המורחבת (localization). בשלב הבא ישנן 2 קונבולוציות בגודל 3×3 ולאחר כל אחת מהן ישנה פונקציית אקטיבציה מסוג RELU.
בפרוצדורה האחרונה בחלק המרחיב משתמשים בקונבולוציה בגודל 1×1 שמטרתה למפות כל וקטור מאפיינים בעל 64 ערכים (הגודל של השכבה הלפני אחרונה) למספר המחלקות שאנחנו רוצים.
האימון והתוצאות
את הרשת הם מאמנים עם מאגר תמונות מתויגות (ז”א לאיזו מחלקה שייך כל פיקסל) עם פונקציית מחיר softmax cross entropy כאשר נותנים משקל גבוה יותר לפיקסלים בגבולות של המחלקות ומשקל המאזן תדירויות פיקסלים ממחלקות שונות:
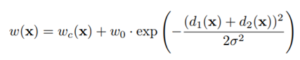
נועד לאזן פיקסלים ממחלקות בתדירויות שונות, ו
הינם המרחק מפיקסל x לגבול של המחלקה הקרובה ביותר או השניה הקרובה ביותר בהתאמה.
במאמר הם אומנם לא מציגים תוצאות על האתגרים המפורסמים אבל כן טוענים לתוצאות מנצחות על DB קטנים בני עשרות תמונות בלבד (לפני אוגמנטציות) בתחום הביולוגיה: צילומים מיקרוסקופיים של מבנים נוירונים, ושל תאים.
קישורים
הסברים, קוד ומודל להורדה של U-Net:
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
מימוש של רשתU-Net ב Tensorflow:
