
מה עושים כשאין מספיק Data ?
כשרוצים לאמן רשת Deep Learning ואין מספיק Data ישנם מספר שיטות מה לעשות, העיקריות הינן:
- – Data Augmentation (למשל בתמונות: סיבובים, הזזות, הרעשות, מחיקות, שינויי הארה)
- – הקטנת המודל
- – יצירת DB סינטטי
- – עזרה לאימון ע”י Data Preprocessing (למשל בתמונות Cropping מתוך הבנה מה חשוב ומה מיותר בתמונה על מנת לסווג)
אבל השיטה שהכי מסקרת בעיני היא לג’נרט (לחולל) Data נוסף באמצעות רשת ג’נרטיבית ייעודית ובלתי קשורה לרשת עצמה אותה רוצים לאמן. על פניו, אינטואיטיבית זה לא נשמע כמשהו מבטיח, כי הרי איך אפשר לייצר נתונים יש מאין באופן כזה שבאמת יחדש או ישפר את האימון ?
רציתי להתעמק ולהבין למה שזה יעבוד ועד כמה זה בכלל משפר תוצאות ?
גיגול קצר הביא אותי לשני המאמרים האלו: (ששניהם אגב יצאו במרץ 2018 ואף אחד מהם לא מצטט את השני)
DATA AUGMENTATION GENERATIVE ADVERSARIAL NETWORKS
בחרתי להתעמק במאמר הראשון מבין השניים (שנקרא בקיצור DAGAN), כי הם מצרפים לו קוד שאפילו רץ לי במכה ראשונה 🙂
בתמונות פנים הבאות ניתן לראות שהתמונות האמיתיות (לקוחות מ VGG-Face) הם רק בעמודה השמאלית הן של הגברים והן של הנשים, ובכל השאר העמודות התמונות מג’נרטות\מזויפות. (ז”א תוצר של DAGAN)

תודה ל DATA AUGMENTATION GENERATIVE ADVERSARIAL NETWORKS
איך בדיוק קורה הקסם ?
הרעיון לקבל תמונה ממחלקה מסוימת ולחולל על בסיסה תמונות נוספות מאותה מחלקה באמצעות Wasserstein GAN (שהינו שיכלול של אלגוריתם GAN).
מדובר על Database המחולק לכמה מחלקות ומטרתנו להגדיל את ה DB כדי לשפר רשת סיווג (אחרת).
הרשת שמגדילה את ה DB מורכבת מGeneratror ו Discriminator.
רשת ה Generator מנסה לשנות\לעוות את התמונה בכל אופן שמצליחה כל עוד התמונה נשארת באותה מחלקה. רשת ה Discriminator תפקידה לקבל זוג תמונות מאותה מחלקה ולהחליט אם הם באמת שייכות לאותה מחלקה או שאחת מהן מזויפת (ז”א תולדה של ה Generator).
התרשים הבא (לקוח מהמאמר) והוא מסביר הכל:

תודה ל DATA AUGMENTATION GENERATIVE ADVERSARIAL NETWORKS
מאמנים רשת Generator (צד שמאל בתרשים) המקבלת רעש גאוסיאני (z) ותמונה אמיתית (xi) ממחלקה c ועל בסיסם לג’נרט תמונה מזויפת (xg). ובמקביל לאמן רשת Discriminator (צד ימין בתרשים) להבדיל בין זוג תמונות אמיתי (xi, xj) ממחלקה c לבין זוג תמונות שאחת מהן אמיתית ואחת מזויפת (xi,xg) כאשר השניה (xg) נוצרה על בסיס הראשונה (xi).
בצד שמאל (הג’ינרוט) משתמשים במקודד-מפענח כאשר המפענח מקבל שירשור של הטלה לינארית ל z (הרעש המוגרל) ושל xi (התמונה האמיתית).
המימוש המוצע
הכותבים מימשו את הרעיון באופן הבא:
ה Generator (המחולק לEncoder ול- Decoder) ממומש ע”י שילוב של UNet ושל ResNet והכותבים קוראים לו UResNet:
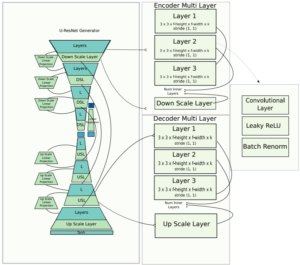
תודה ל DATA AUGMENTATION GENERATIVE ADVERSARIAL NETWORKS
ה Discriminator ממומש ע”י DenseNet.
סדרי גודל ותוצאות
ראשית נציין עובדה חשובה שכשהשוו תוצאות של ה classifier, בתוצאות ללא ה Gan Augmentation הם כן השתמשו ב Augmentation קלאסי (שכלל: סיבובים של 90 מעלות, הזזות, הוספת רעש לבן), ובתוצאות ים ה Gan Augmentation הם עשו גם Augmentation קלאסי, מה שאומר שהגישה של ה Gan Augmentation באמת תרמה ביחס להוספת תמונות באופן רגיל.
הבחינה נעשתה על שלושה אתגרי קלאסיפיקציה:
האחד במאגר Omniglot שהינו מאגר של עשרות אלפי תמונות של 1623 אותיות שונות מחמישים שפות שונות בכתב יד. השני ממאגר תמונות פנים VGG-Face והשלישי ממאגר תמונות כתב יד EMNIST שהינו הרחבה של MNIST הפופולארי.
השיפור בביצועי הקלאסיפיקציה משמעותי:
| הבעיה | עם Augmentation רגיל | עם Gan Augmentation |
| Omniglot | 69% | 82% |
| EMNIST | 73.9% | 76% |
| VGG-Face | 4.5% | 12% |
הריצה מאוד ארוכה אגב: 500 epochs על עשרות אלפי תמונות, חייבים כמה GPUים כדי להריץ בזמן סביר.
קישורים
ניתן להשתמש ב-DAGAN להרחבת DB כלשהוא של תמונות, כקופסה שחורה באמצעות הקוד הבא:
https://github.com/AntreasAntoniou/DAGAN
